#19 Expert: Wie kann man Infografiken mit GPT Vision analysieren um Blogpost/Audios/Videos zu erstellen?
Worum geht es in diesem Artikel?
In dem Post zeige ich wie man Infografiken mit GPTVision in einem zweistufigen Prompt Ansatz auswerten kann. Die Umsetzung erfolg mit No-Code Tools, Airtable, Make, OpenAi und GPTVision
Gestern habe ich beschrieben wie man mit GPT Vision jede Slide einer Powerpoint/PDF analysieren kann.
Infografiken sind oft nicht selbsterklärend und geben einen Inhalt sehr detailliert wieder. Ohne Kontext zu haben und eine Infografik in 2-3 Minuten anschauen hat für die meisten Lerner keinen Wert, deshalb möchte ich aus Infografiken wieder Content generieren, im besten Fall daraus eine neue Präsentation/BlogPost/Audio/Video zu erstellen.
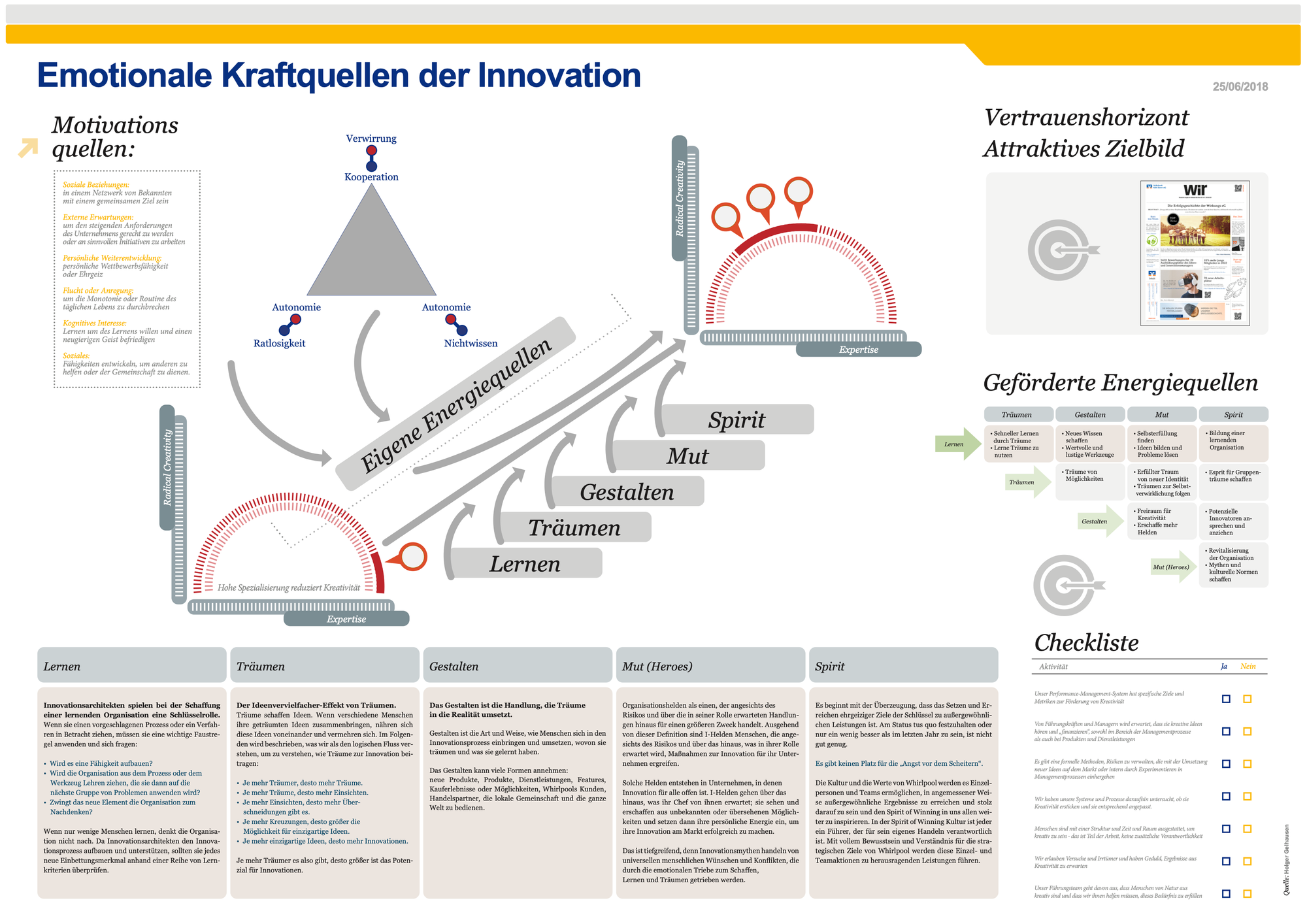
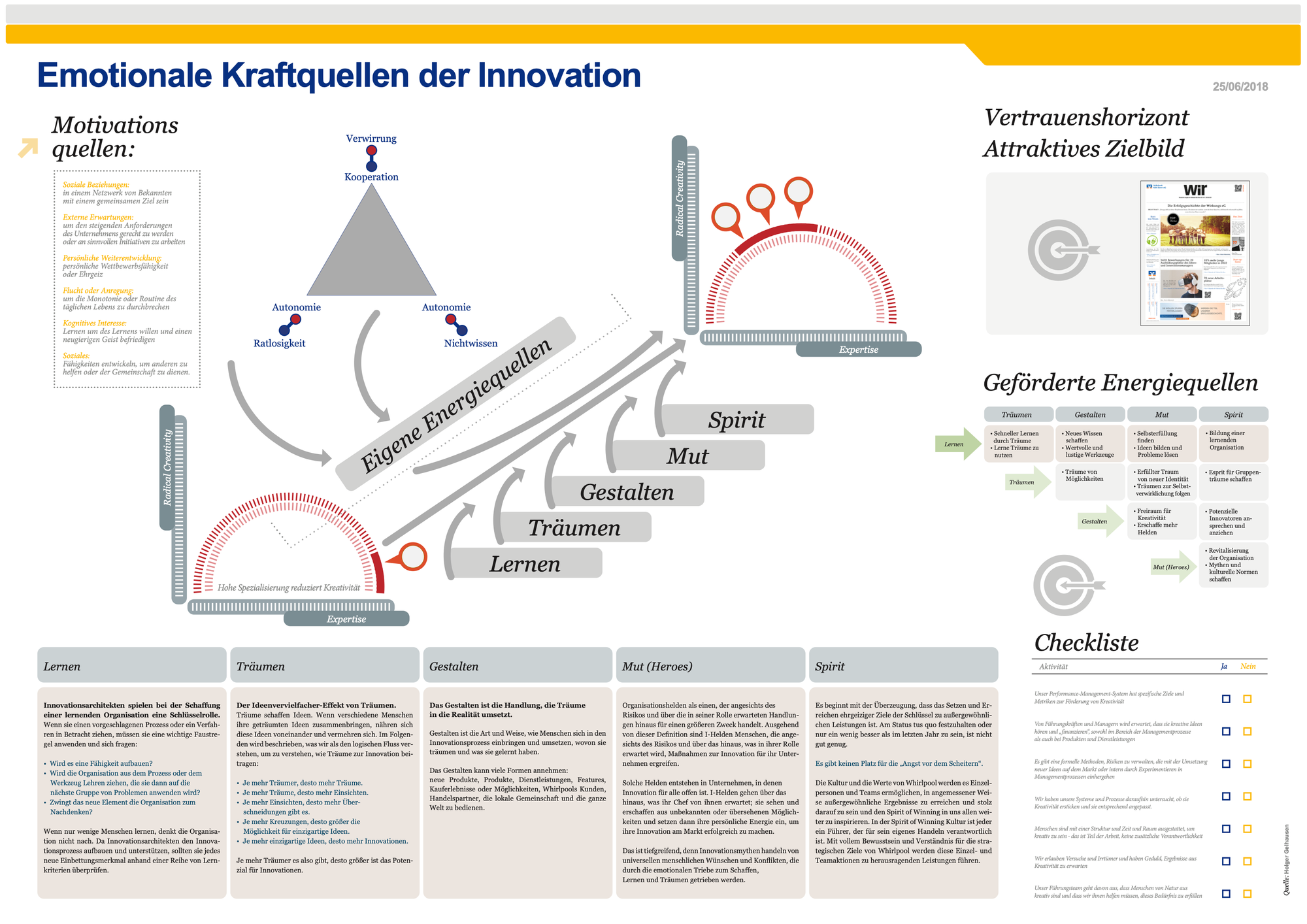
Bei umfangreichen Infografiken wie dieser, die ich 2018 erstellt habe, gelangt GPT Vision aus dem Konzept. Einfach gesprochen GPT Vision vergisst Textelemente aus der Infografik zu beschreiben.
Die Whirlpool Innovationsstory
Die Infografik beschreibt im Detail, angereichert mit Elementen von mir, die Innovationsgeschichte von Whirlpool. Eines der besten Innovationskonzepte die ich kenne. Das besondere an dem Konzept ist, das der CEO sagte jeder Mitarbeiter kann innovieren. Die Haltung führte dazu das in der Linie neue Produkte entwickelt wurden. Eine grandiose Geschichte.
Dieses Buch lohnt sich zu lesen, wenn man Innovationen im Unternehmen treiben möchte.

Von diesen Infografiken habe ich ganz viele in meinen Dateien. Hier ein kurzer Überblick aus dem lokalen Speicher, da ich nicht alles repliziert habe, Dopplungen abziehe, werde ich in dem Bereich 150-200 Infografiken liegen.

Grund genug zu schauen wie ich das optimieren kann.
Nach dem ich drei – vier Stunden an den Prompts gebastelt habe, bin ich zu folgenden Drehbuch gekommen.
Ich arbeite mit zwei Prompts:
- Ein Prompt zu GPTVision sucht die Abschnitte im Bild
- Der zweite Prompt fokussiert ich auf die Abschnitte und gibt nur diesen Abschnitt heraus.
Bei dieser Infografik hat das super funktioniert nach mehreren Anläufen die Prompts zu gestalten.
Wie gestalte ich die Prompts?
Prompt 1
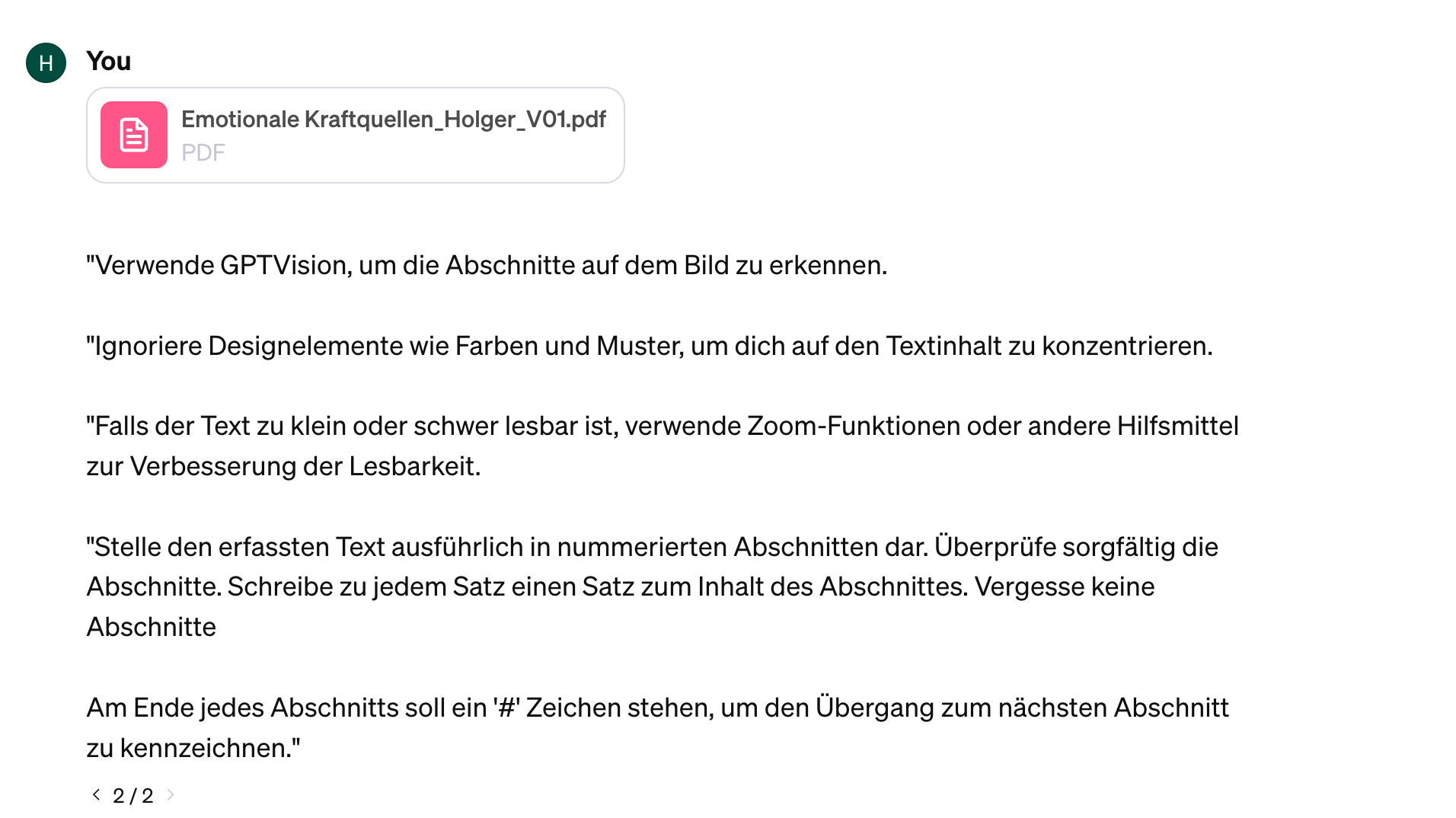
Ergebnis 1

Das Ergebnis ist prima, die Abschnitte wurden richtig erkannt.
Prompt 2
Liste den ganzen Text mit einem Titel in dem Abschnitt auf: (((Organisationshelden und Innovationskultur: Es wird die Rolle von „Organisationshelden“ beschrieben, die für Innovation über ihre erwarteten Rollen hinausgehen, und wie eine Kultur der Innovation gefördert werden kann.. )))
Gebe nur den Text in dem Abschnitt vollständig aus. Mache keine Bewertung oder Einleitung. Vergesse kein Wort und setze Absatzendemarken um den Text lesbarer zu machen.
Der Text in den ((( ))) ist die Variable die mit den Abschnitten gefüllt werden muss.
Ergebnis 2

Der Text ist vollständig analysiert wurden. Jetzt brauche ich nur noch eine Automatisierung zu bauen, die auf Knopfdruck die ganze Infografik ausliest.
Wie sieht die Automatisierung aus?
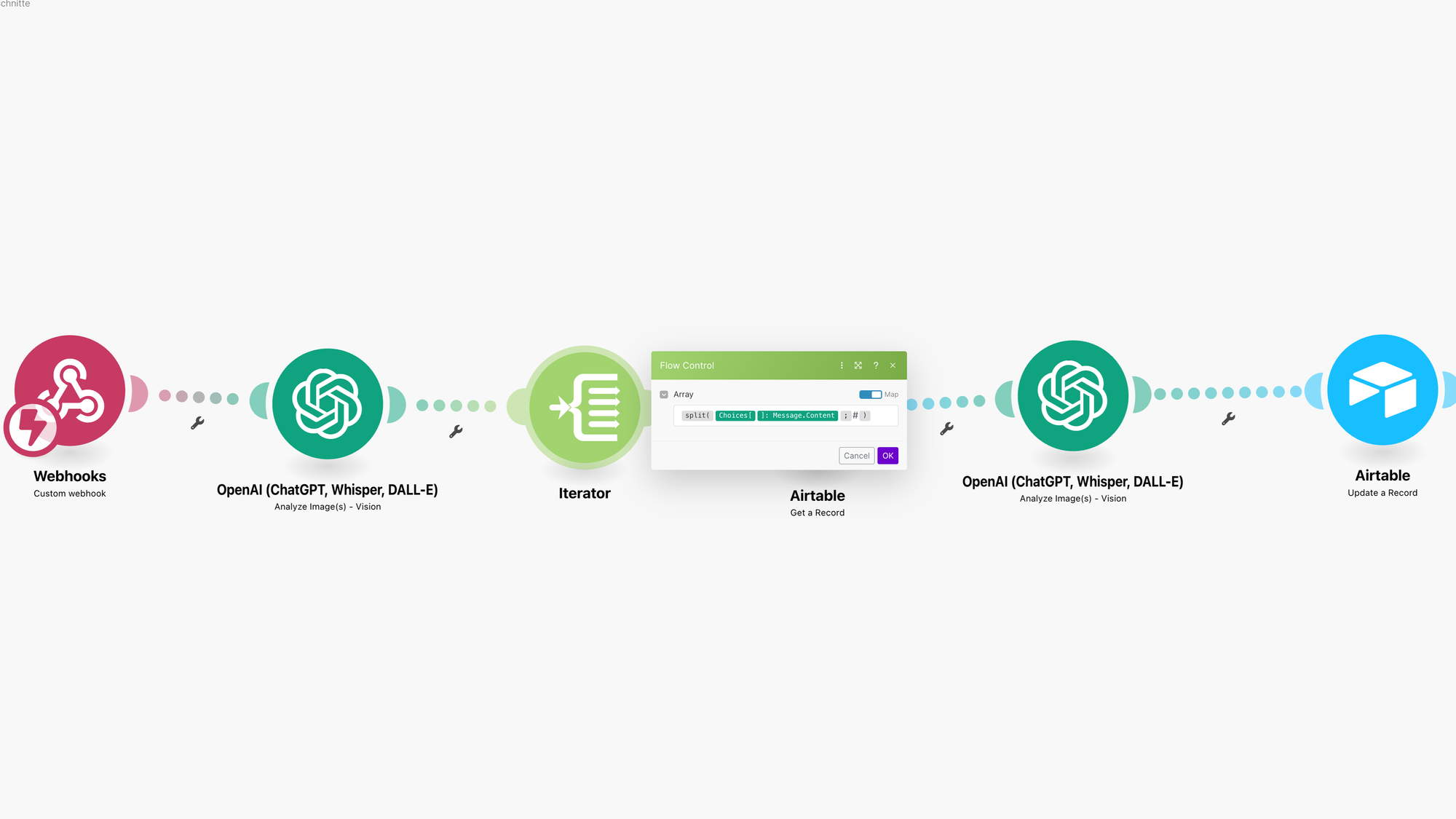
Das ist ein einfaches Make Szenarion mit den wichtigen fünf Schritten, zwischen 2 und 5 wird eine Schleife durchlaufen abhängig von der Anzahl der Abschnitte.

Schritt 1
Hier wird das Bild auf Abschnitte untersucht
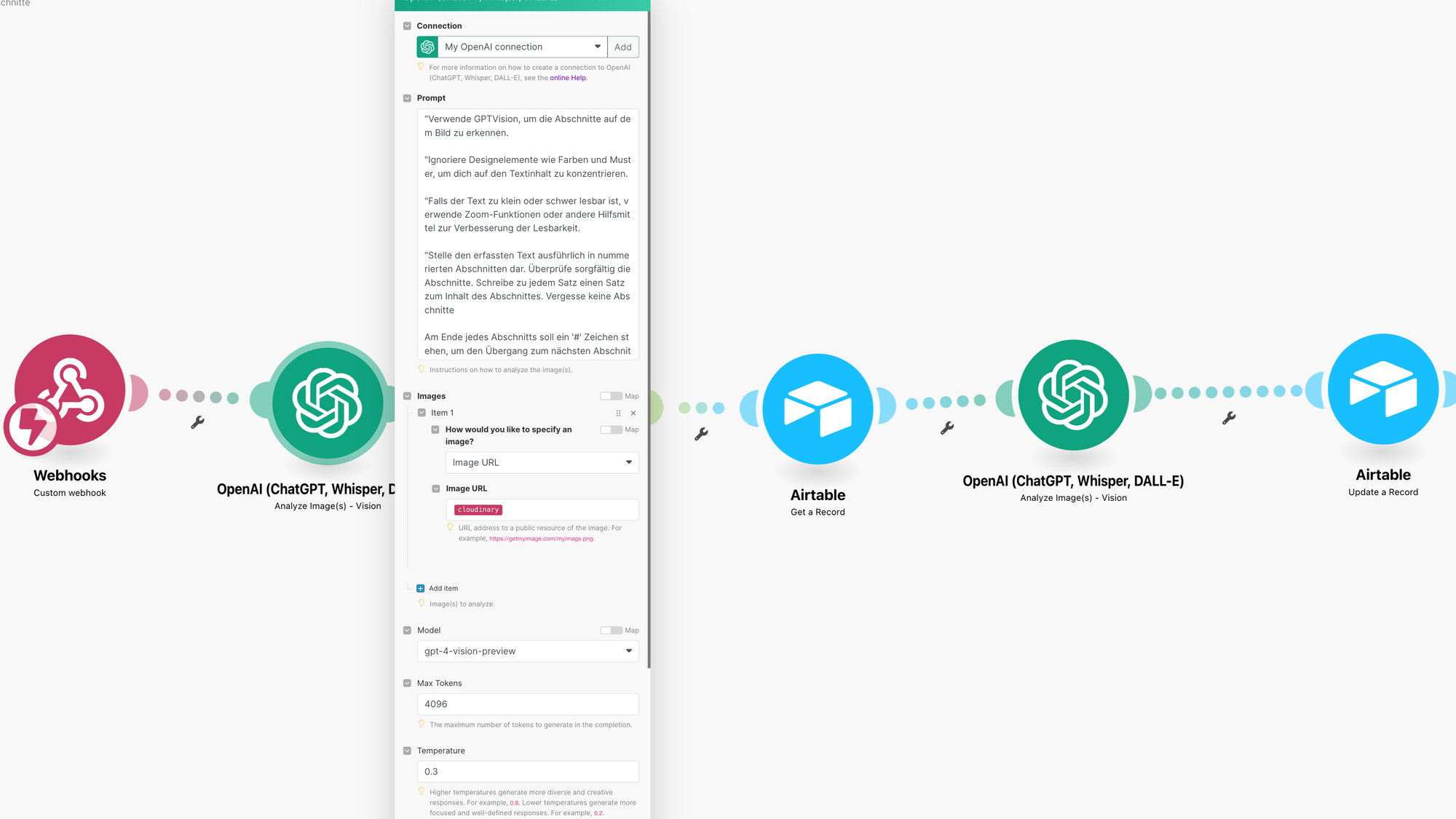
Schritt 2
Die vielen Abschnitte werden in eine Schleife mit einem Iterator gebracht, damit jeder Abschnitt untersucht werden kann.
Schritt 3
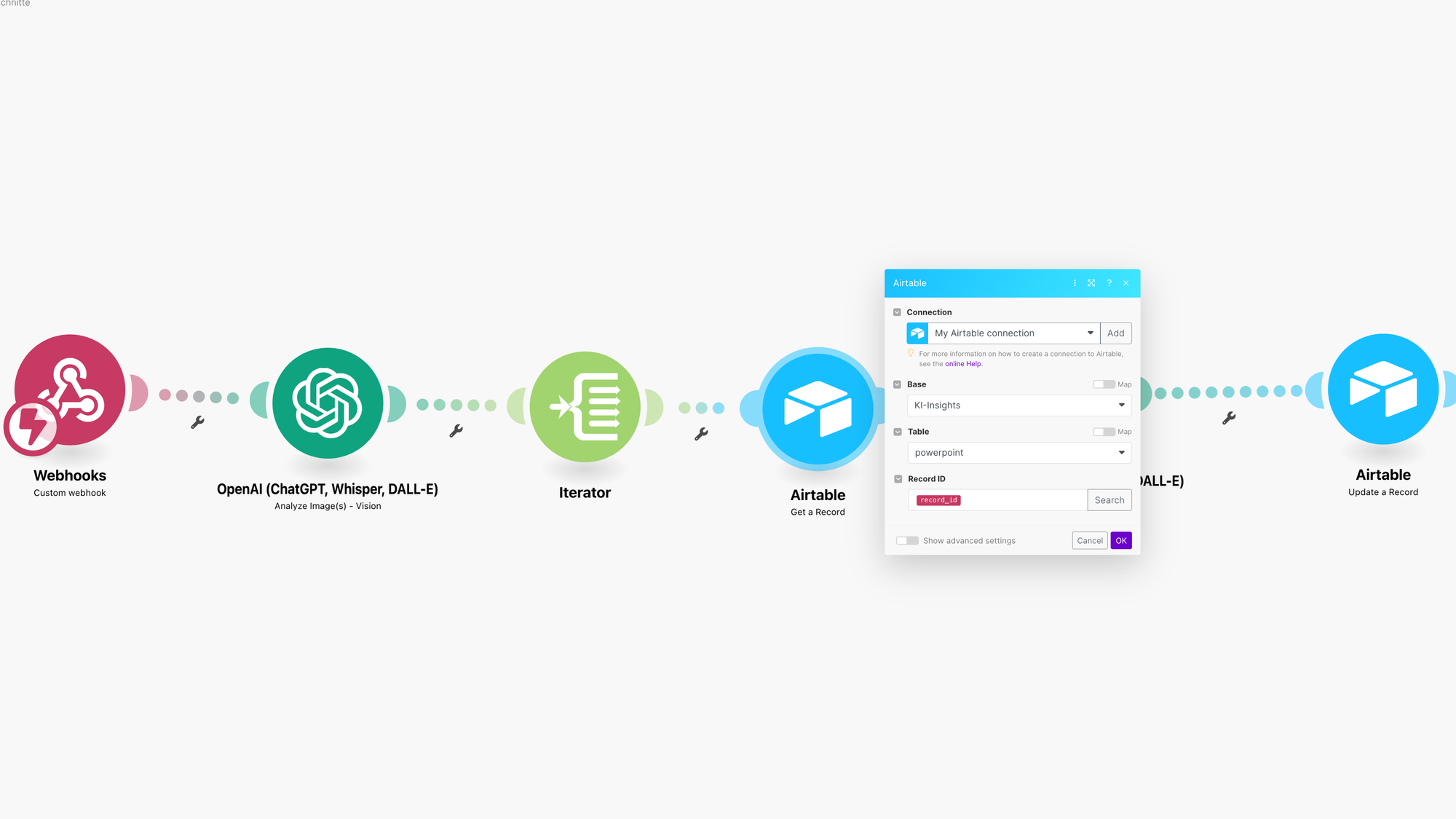
Ich hole wir den Wert der Variable Vision Detail, die ich am Ende des Workflow brauche um so etwas wie Append Variable zu machen.
Schritt 4
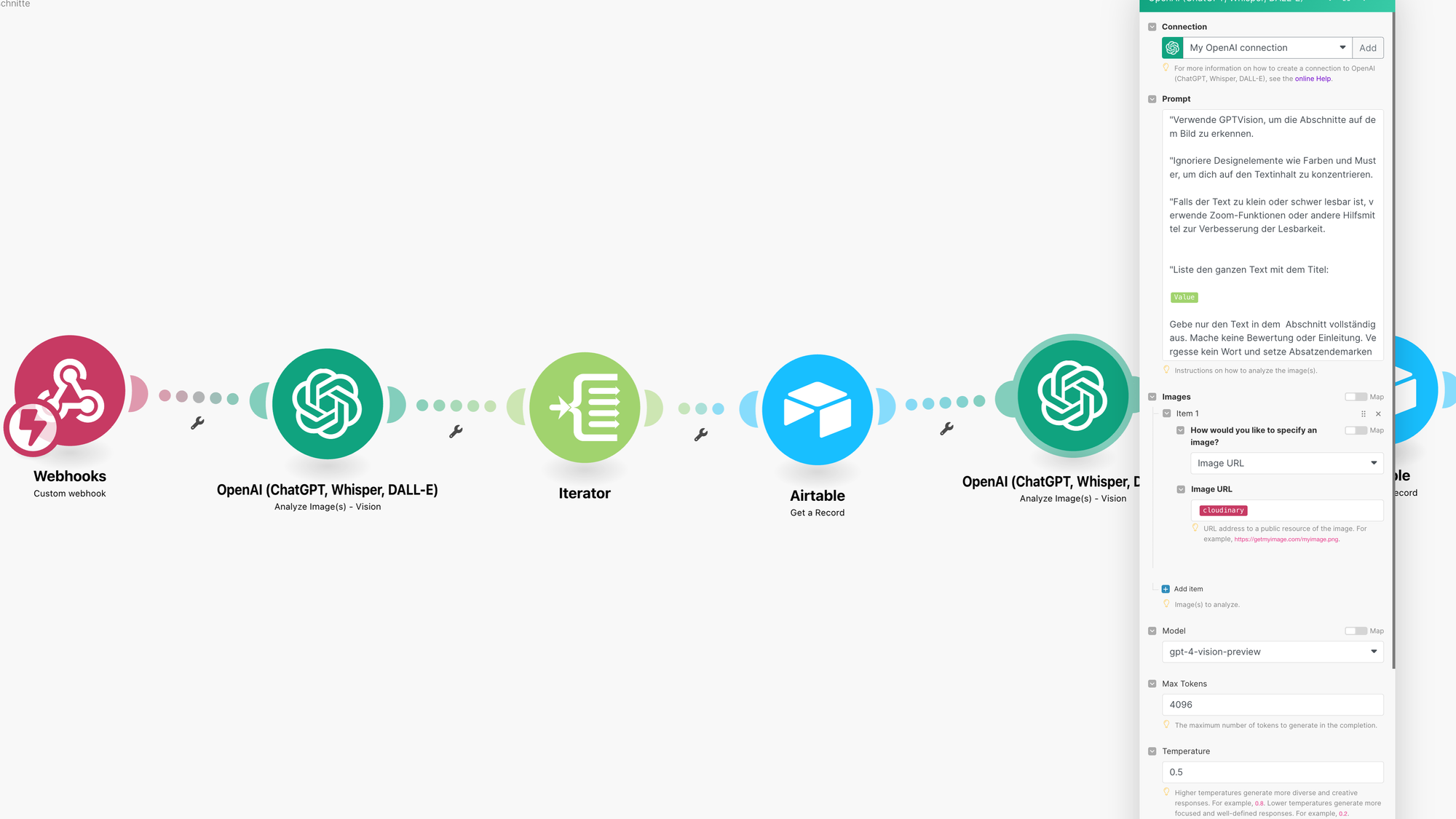
Hier wird der Text des Abschnittes untersucht
Schritt 5
Der Abschluss, der Wert des jeweiligen Abschnitts wird in Airtable geschrieben.
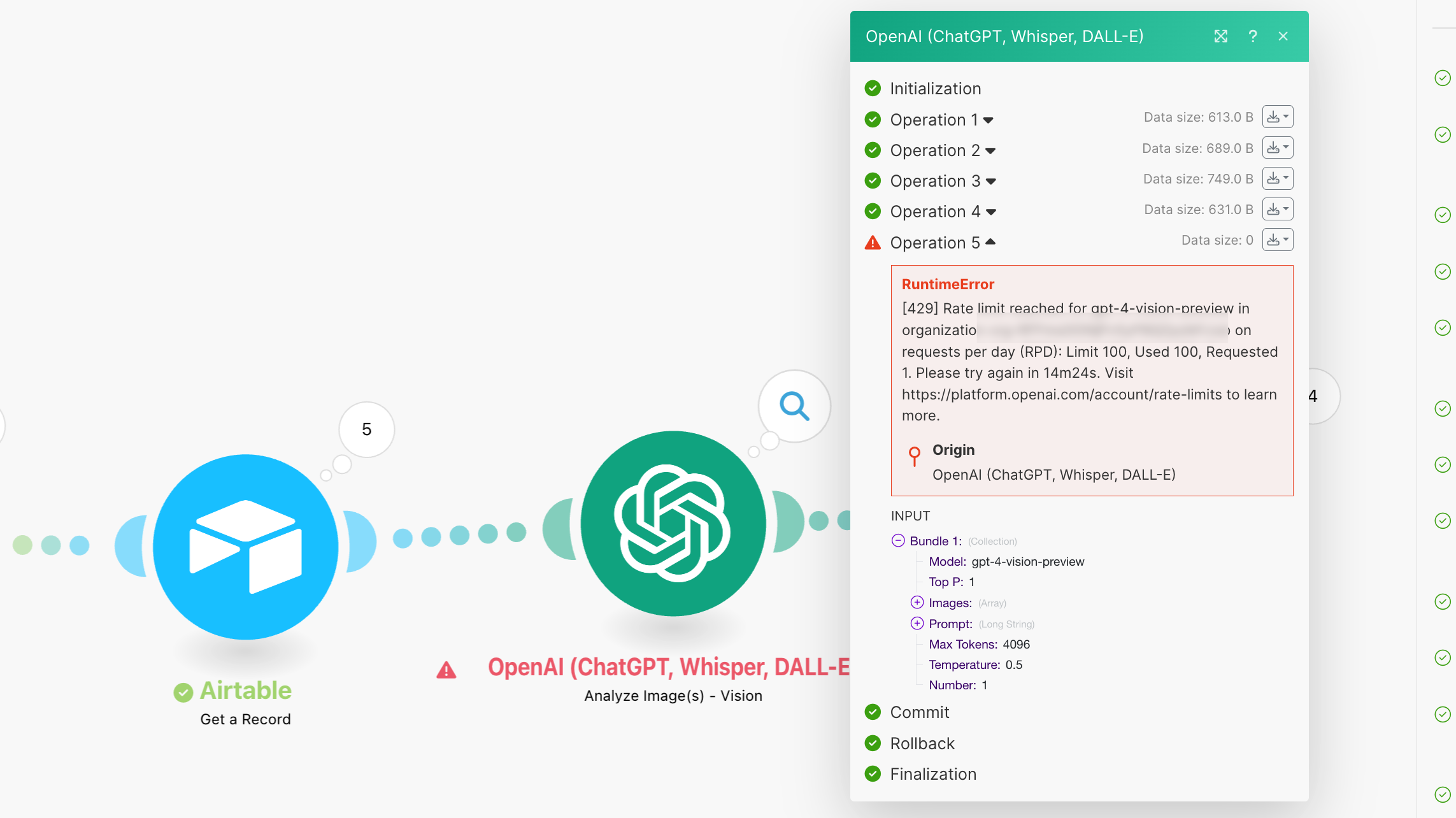
Nachdem ich lange an den Prompts gefeilt hatte, war mein Maximum an GPT Vision aufrufen erschöpft
Ergebnis
Mit dem mehrstufigen Prompt Ansatz für GPTVison kann ich nun auch Infografiken wunderbar auslesen. Die Test waren sehr erfolgreich.
Jetzt geht es in den nächsten Schritten zur Verarbeitung des Contents für BlogPosts/Audio/Video Formate





