#59 Expert: Alibaba Qwen-VL-Max und LLava 34 b schlagen GPTVision
Worum geht es in diesem Artikel?
Ich möchte meine ganzen Bilder und Screenshots auf der Festplatte erkennen lassen. Wie kann ich das kostengünstig umsetzen?
Ich möchte viele meine Infografiken auf der Festplatte und Screenshots lokal erkennen lassen. Wie mache ich das kostengünstig?
Hier in den Blogposts habe ich gezeigt wie man Powerpoints oder auch Infografiken automatisch mit GPTVision erkennen kann.
Wie immer, die Kosten von Cloud-Systemen können den Preis ganz nach oben treiben. Für ein Unternehmen das die eigenen Datenschätze heben will kommen schnell mehrere tausend Euro im Monat zusammen.
Wie man eine Bilderkennung einfach mit GPT Vision durchführt?
GPTVision ist ein sehr gutes und schnelles System. Schaut in das Bild, eine ganz klare Erkennung und gute Erkennung.

Wie kann ich das lokal durchführen?
Ich habe verschiedene Alternativen durchgetestet
- Ollama mit den verfügbaren Modellen wie llava 34 B
- lmstudio – habe ich nicht ans laufen bekommen, dafür reicht mein Wissen nicht.
- Llava direkt über Github installiert – stundenlang probiert, versuche ich mal auf einem Windows mit Nvidia
Fazit lokal: Die Ollama llava 34 B Instanz scheint andere Parameter zu haben als die Version bei GitHub

Hier werde ich mal nachfragen bei Ollama. Für die Standardaufgaben wird llava 34 B vielleicht gut genug funktionieren.
Wie Alibaba Qwen-VL-Max GPT Vision schlägt.
Ich habe heute Stunden damit verbracht Llava 34B über GitHub zu installieren. Ich bekam immer den Fehler „Network Error DUE….“ Unten rechts auf dem Bild.
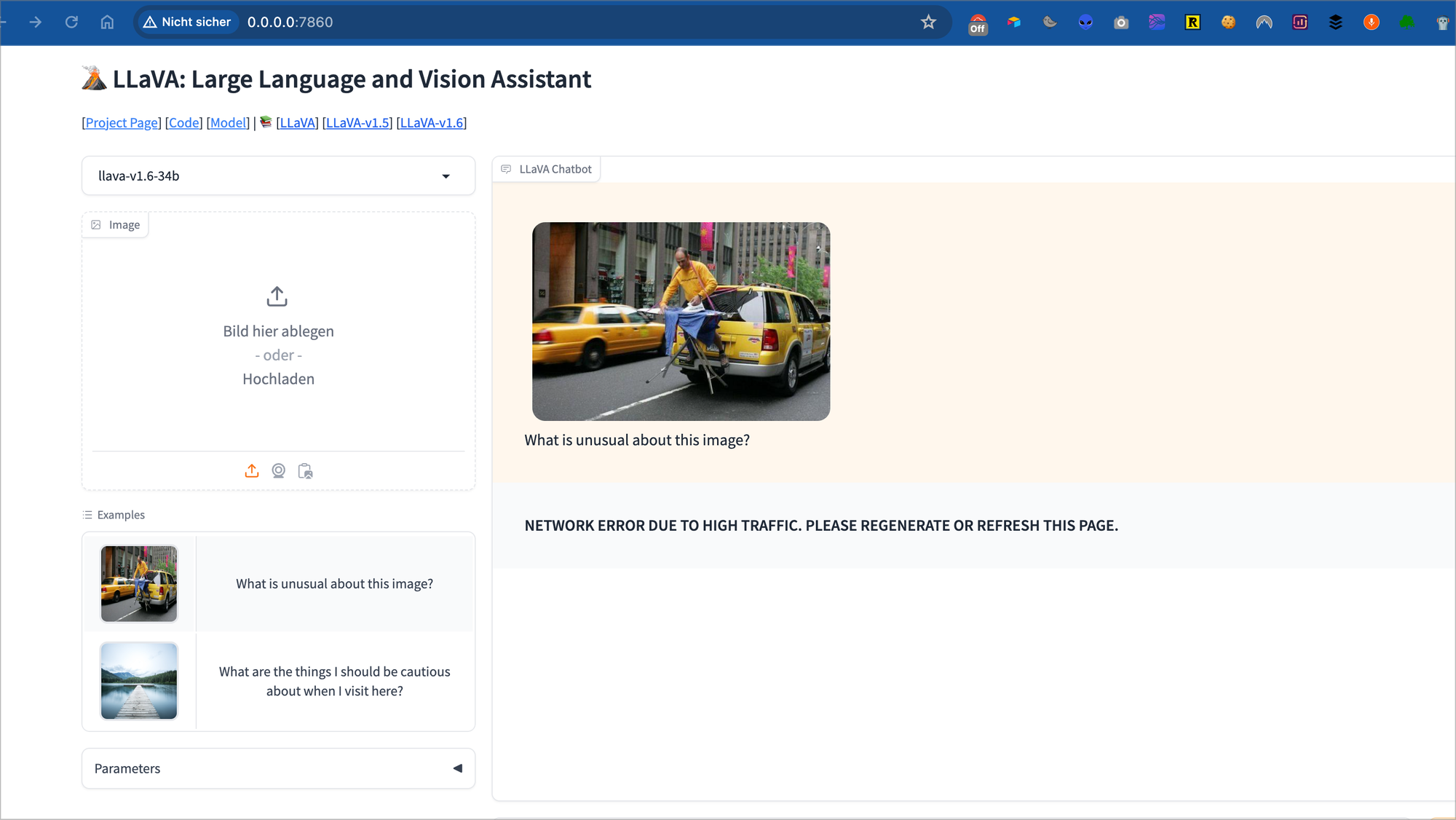
Dieser Fehler ist die wichtigste Information auf dem Bild. Dieses Bild nehme ich als Grundlage um die Cloud-Modelle zu testen.
Wie GPT Vision das Bild beschreibt
GPTVision beschreibt das Bild und erkennt den Fehler nicht.

Auch auf Nachfragen erkennt GPTVision den Fehler nicht.

Lava llava-v1.6-34b
Erkennt auch beim ersten Mal den Fehler und beschreibt das Bild

Aber Alibaba
Alibaba hat verschiedene KI-Modelle auf Hugginface und Github bereitgestellt. Das Vision Modell ist Qwen-VL und gib es in mehreren Größen auf HuggingFace und Github, ich habe das Plus- und Max Modell getestet.
Qwen-VL-Plus erkennt den Fehler nur auf Nachfrage

Qwen-VL-Max erkennt sofort den Fehler
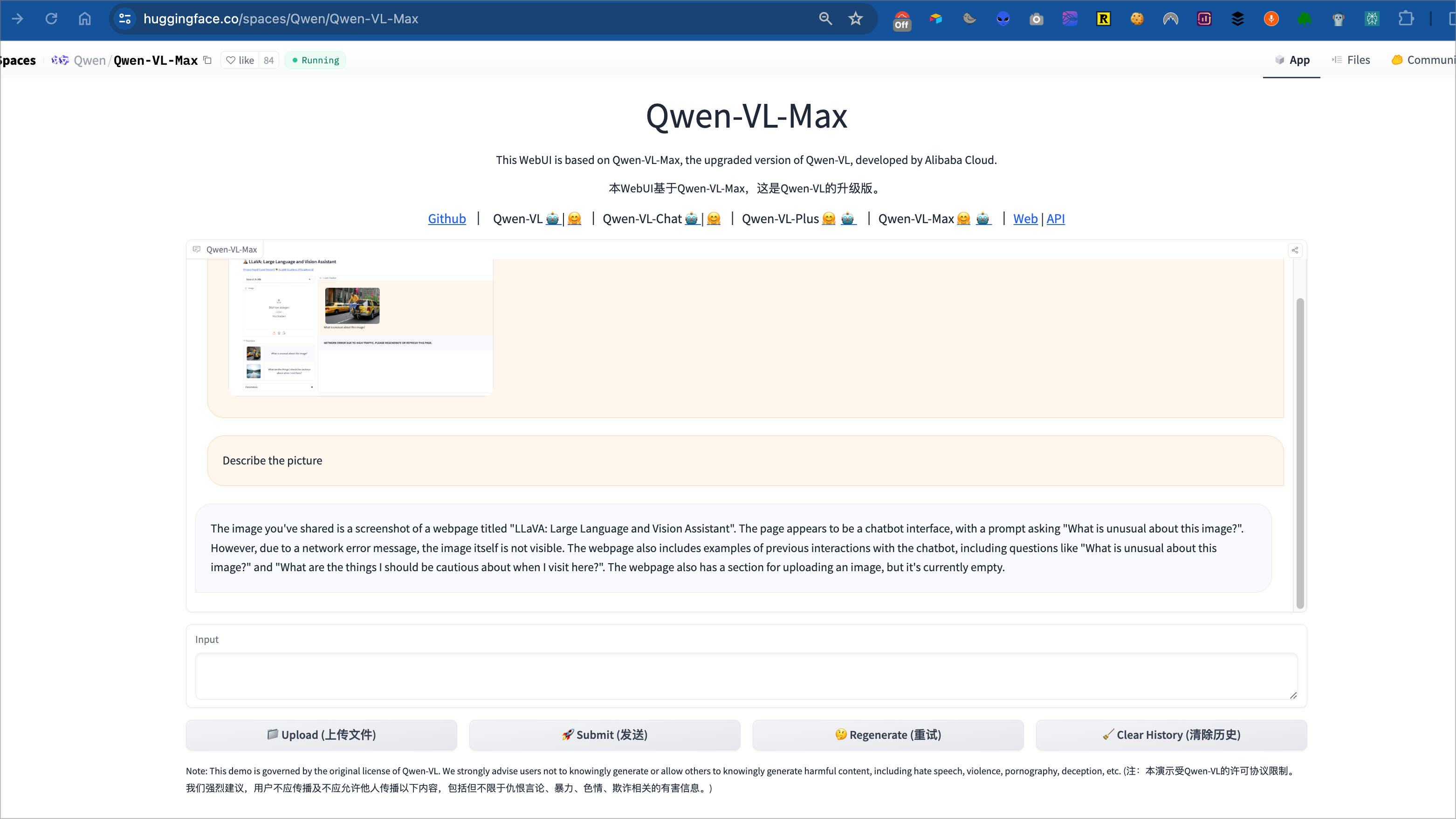
Fazit
Im Bereich lokaler Bilderkennung werden wir noch viele neue LLMs in den nächsten Monaten finden, die mit GPTVision in manchen Fällen gleich auf ziehen und schlagen. Hier wird es immer ein Rennen geben zwischen den LLM Anbietern.
Das zwei Modelle GPT Vision schlagen hätte ich nicht gerechnet.
Ich werde mit Ollama mir einen Skript bauen lassen und die Ergebnisse von 30 Bilder mit GPT Vision vergleichen und dann eine größere Anzahl von Bilder analysieren lassen.