#157 Wie man Youtube Videos Kapitelweise analysiert?
Worum geht es in diesem Artikel?
Gestern habe ich das fantastische Video von Andrew Hubermann auf Youtube über „Optimale Protokolle zum Lernen“ entdeckt. Ungefähr 6,2 Millionen Aufrufe und ca. 2000 Kommentare, das Video scheint einen Nerv zu treffen.
Ich möchte gerne verstehen, welche Lernmethoden ich in meinen Trainings zusätzlich einbauen / nutzen kann. In der Lernwelt passiert so viel Neues.
Deshalb habe ich einen KI-Workflow gebaut der kapitelweise das Video analysiert und mir auch die neuesten Forschungsergebnisse dazu sucht. Ich habe das noch mit meiner Spezialfrage an den Workflow angereichert, das ich auch direkt wissen möchte, welche Tips jedes Kapitel für die Optimierung der Trainings hat.
Das ist der Workflow als Übersicht:
Die Schritte im Detail:
- Ich lege ein Google Doc an
- OpenAI hat die Aufgabe die Youtube Beschreibung zu laden um daraus Chapters zu erstellen
- Der Iterator holt sich jedes Chapter
- Claude führt eine Analyse für jedes Chapters aus
- Perplexity sucht nach 3-5 Artikeln zu jedem Chapter
- Ein Sleep Modul sonst meckert Claude zu viele Token/min
- Die Ergebnisse jeden Chapters werden in das Google Doc eingetragen
Details zu dem Workflows
OpenAI erstellt Arrays
Der Iterator geht über die Arrays
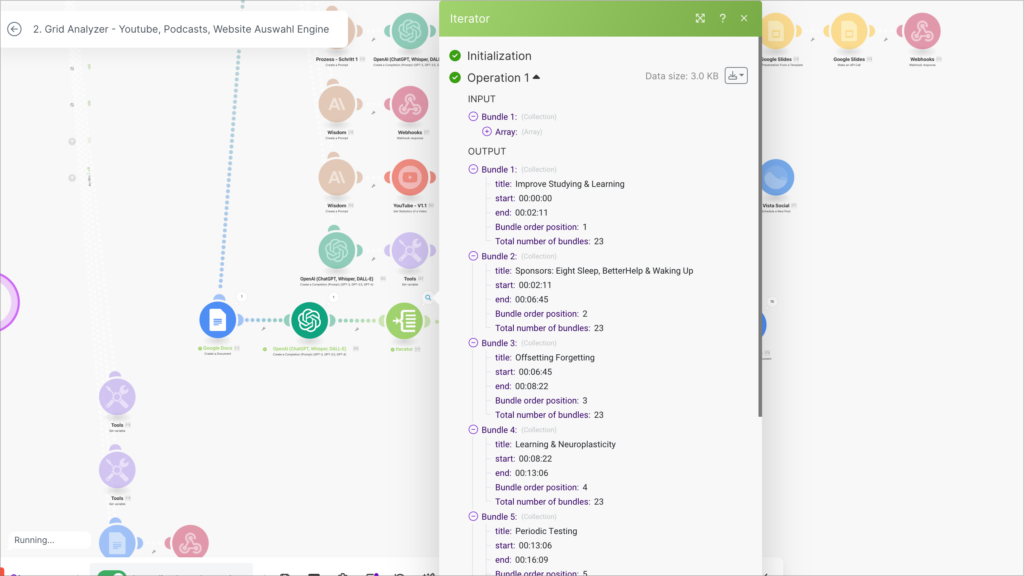
Claude analysiert das Chapter
Perplexity sucht nach Artikeln
Ergebnis:

Wie mache ich das Google Doc schöner?
Man kann Google Docs auch mit einem HTML Format erstellen und dann direkt die Formatierungen einbringen, einfacher ist manchmal der Ansatz die Formatierung in Google Doc zu erstellen.
Aufgabe: Ich möchte das jede Chapter Nummer in Überschrift 2 gebracht wird und # in Überschrift 3 usw.
Das einfachste ist Claude fragen um so ein Script zu erstellen. ich möchte in Google Doc ein neues Menü und dann einfach klicken, kann man auch über die api automatisieren.
function formatChapterHeadings() {
try {
// Get the active document
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
Logger.log("Dokument geöffnet");
// Get all paragraphs
var paragraphs = body.getParagraphs();
Logger.log("Anzahl Paragraphen: " + paragraphs.length);
// Loop through paragraphs
for (var i = 0; i < paragraphs.length; i++) {
var paragraph = paragraphs[i];
var text = paragraph.getText();
Logger.log("Prüfe Text: " + text);
// Check for Chapter line
if (text.trim().startsWith("Chapter")) {
Logger.log("Chapter Zeile gefunden: " + text);
// Extract number between "Chapter" and ":"
var number = text.match(/Chapter\s+(\d+):/);
if (number && i + 1 < paragraphs.length) {
var chapterNum = number[1];
Logger.log("Kapitelnummer gefunden: " + chapterNum);
// Get and modify next line
var nextParagraph = paragraphs[i + 1];
var titleText = nextParagraph.getText();
var newTitle = chapterNum + ". " + titleText;
Logger.log("Neuer Titel wird: " + newTitle);
// Apply changes
nextParagraph.setText(newTitle);
nextParagraph.setHeading(DocumentApp.ParagraphHeading.HEADING2);
paragraph.removeFromParent();
Logger.log("Änderungen angewendet");
}
}
}
Logger.log("Script erfolgreich beendet");
// Show completion message
DocumentApp.getUi().alert("Chapter Formatierung abgeschlossen!");
} catch (error) {
Logger.log("Fehler: " + error.toString());
DocumentApp.getUi().alert("Fehler: " + error.toString());
}
}
function formatMarkdownHeadings() {
try {
// Get the active document
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
// Get all paragraphs
var paragraphs = body.getParagraphs();
Logger.log("Dokument geladen. Anzahl Paragraphen: " + paragraphs.length);
// Process each paragraph
for (var i = 0; i < paragraphs.length; i++) {
var paragraph = paragraphs[i];
var text = paragraph.getText();
// Check for ## heading (h4)
if (text.startsWith('##')) {
// Remove the ## and format as H4
var newText = text.substring(2).trim();
paragraph.setText(newText);
paragraph.setHeading(DocumentApp.ParagraphHeading.HEADING4);
Logger.log("H4 formatiert: " + newText);
}
// Check for single # heading (h3)
else if (text.startsWith('#')) {
// Remove the # and format as H3
var newText = text.substring(1).trim();
paragraph.setText(newText);
paragraph.setHeading(DocumentApp.ParagraphHeading.HEADING3);
Logger.log("H3 formatiert: " + newText);
}
}
// Delete all remaining # characters from the document
var documentText = body.editAsText();
var text = documentText.getText();
while (text.indexOf('#') !== -1) {
var hashIndex = text.indexOf('#');
documentText.deleteText(hashIndex, hashIndex);
text = documentText.getText();
}
// Show completion message
DocumentApp.getUi().alert("Markdown Formatierung abgeschlossen!");
Logger.log("Script erfolgreich beendet");
} catch (error) {
Logger.log("Fehler: " + error.toString());
DocumentApp.getUi().alert("Fehler: " + error.toString());
}
}
function removeAsterisks() {
try {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
// Delete all ** characters from the document
var documentText = body.editAsText();
var text = documentText.getText();
// First try to replace consecutive ** with empty string
while (text.indexOf('**') !== -1) {
var doubleAsteriskIndex = text.indexOf('**');
documentText.deleteText(doubleAsteriskIndex, doubleAsteriskIndex + 1);
text = documentText.getText();
}
// Then clean up any remaining single *
while (text.indexOf('*') !== -1) {
var asteriskIndex = text.indexOf('*');
documentText.deleteText(asteriskIndex, asteriskIndex);
text = documentText.getText();
}
DocumentApp.getUi().alert("Alle ** wurden entfernt!");
Logger.log("Asteriske erfolgreich entfernt");
} catch (error) {
Logger.log("Fehler: " + error.toString());
DocumentApp.getUi().alert("Fehler: " + error.toString());
}
}
// Add menu items
function onOpen() {
try {
var ui = DocumentApp.getUi();
ui.createMenu('Dokument Format')
.addItem('Format Chapter Headings', 'formatChapterHeadings')
.addItem('Format # Headings', 'formatMarkdownHeadings')
.addItem('Entferne **', 'removeAsterisks')
.addToUi();
Logger.log("Menü erstellt");
} catch (error) {
Logger.log("Fehler beim Menü erstellen: " + error.toString());
}
}Als Chatgpt auf den Markt kam, habe ich öfters versucht in der Google Script Language mir ein Script bauen zu lassen, die Ergebnisse waren schlecht. Jetzt funktioniert das tadellos.
Fazit mit Ergebnis
Zusätzliche Optimierungen, später mal.:
- Die wichtigsten Kommentare analysieren
- Die Studien auch passend runterladen und eine Wissensdatenbank bringen
- Einen konkreten Workflow bauen der mit als Input ein Lernthema gibt und dann die passenden Lernformate baut.
Hier der Link zu dem Google Document
Ich bin mit dem kleinen Workflow schon sehr zufrieden und kann mir die Ergebnisse in Ruhe anschauen und mit und Dr. Yvonne Konstanze Behnke , Matthias Wienecke , Alfred Rochel, Martin Lindner und Lars Herrmann + sovielen mehr diskutieren. Danke für den Austausch.