#152 Strukturierte Wissensdatenbanken erstellen: Dein Schritt-für-Schritt-Guide
Worum geht es in diesem Artikel?
Ich zeige wie man eine Filmdatenbank mit Meta-Informationen aufbaut und Perplexity und OpenAI mit structured Output dafür nutzt
Viele Unternehmen haben Schwierigkeiten, ihre Daten zu verstehen, weil die Meta-Daten fehlen. Mit dem strukturierten Output von OpenAI wird das nun einfach.
Nehmen wir an, ich möchte eine Film-Datenbank erstellen und alle Filme transkribieren. Die DVDs habe ich, aber ich bin zu faul, die Meta-Daten für jeden Film zu suchen. Also bauen wir einen KI-Workflow.
Wie sieht ein Workflow aus?
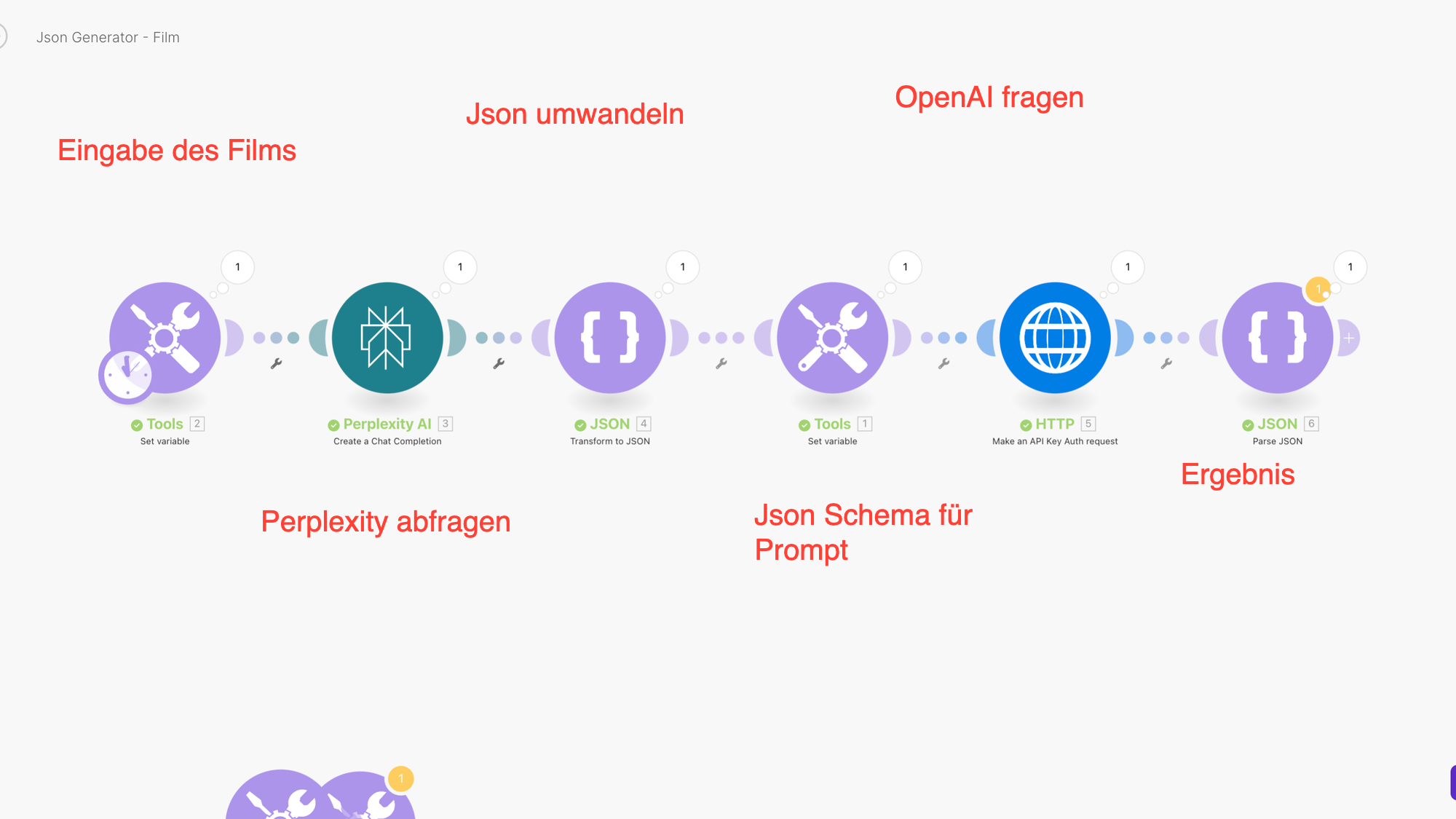
Was brauche ich?
- Eine JSON-Struktur, die OpenAI mit einem strukturierten Output anreichert.
- Ein Prompt, der schrittweise ein solches JSON-Format entwickelt.
- Ein Überprüfungsprompt, der das JSON-Format nochmals prüft.
Ich habe mir die beiden Json Generatoren mit Claude entwickelt.
Ein Ausschnitt aus dem Dialog:
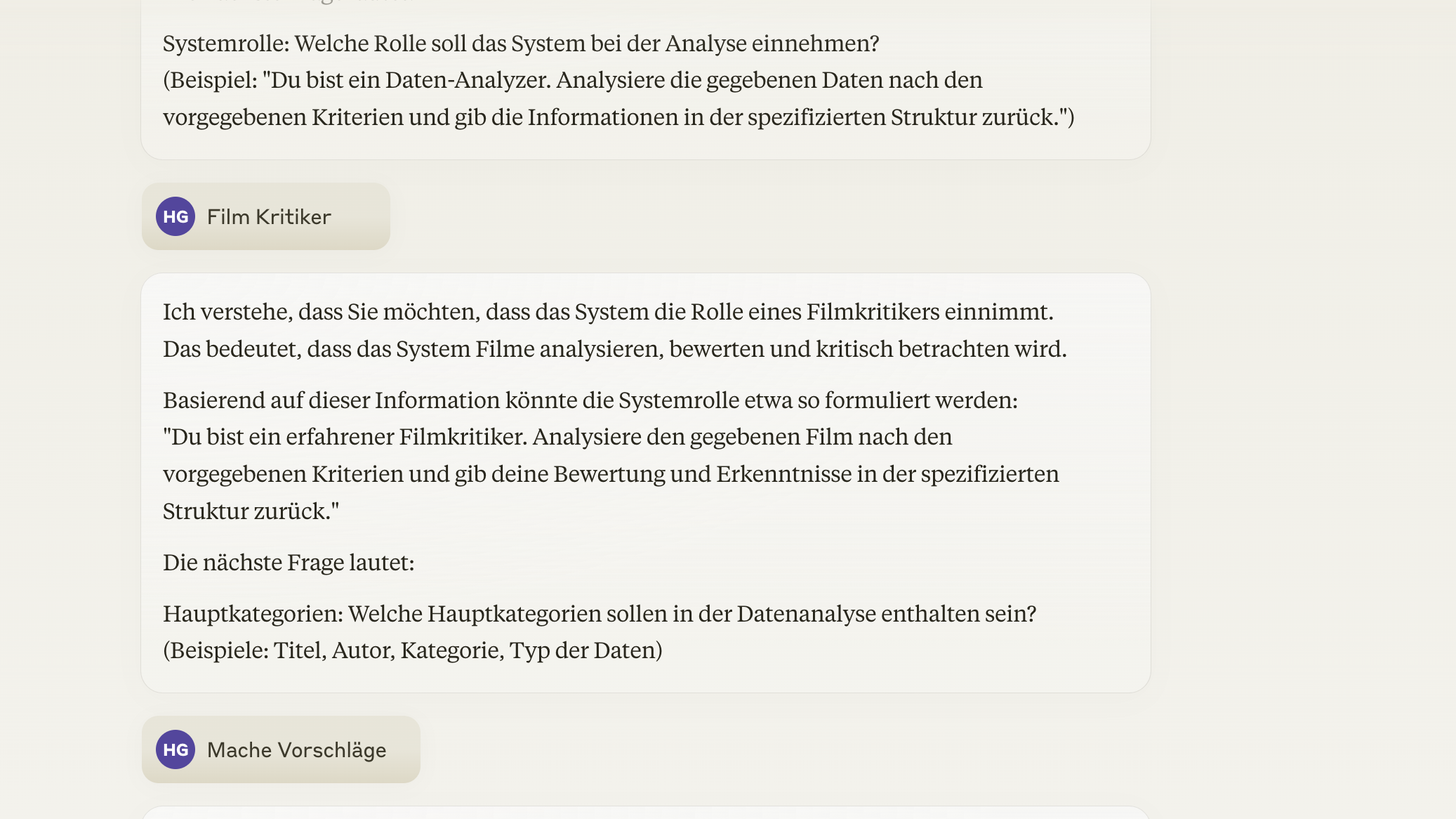
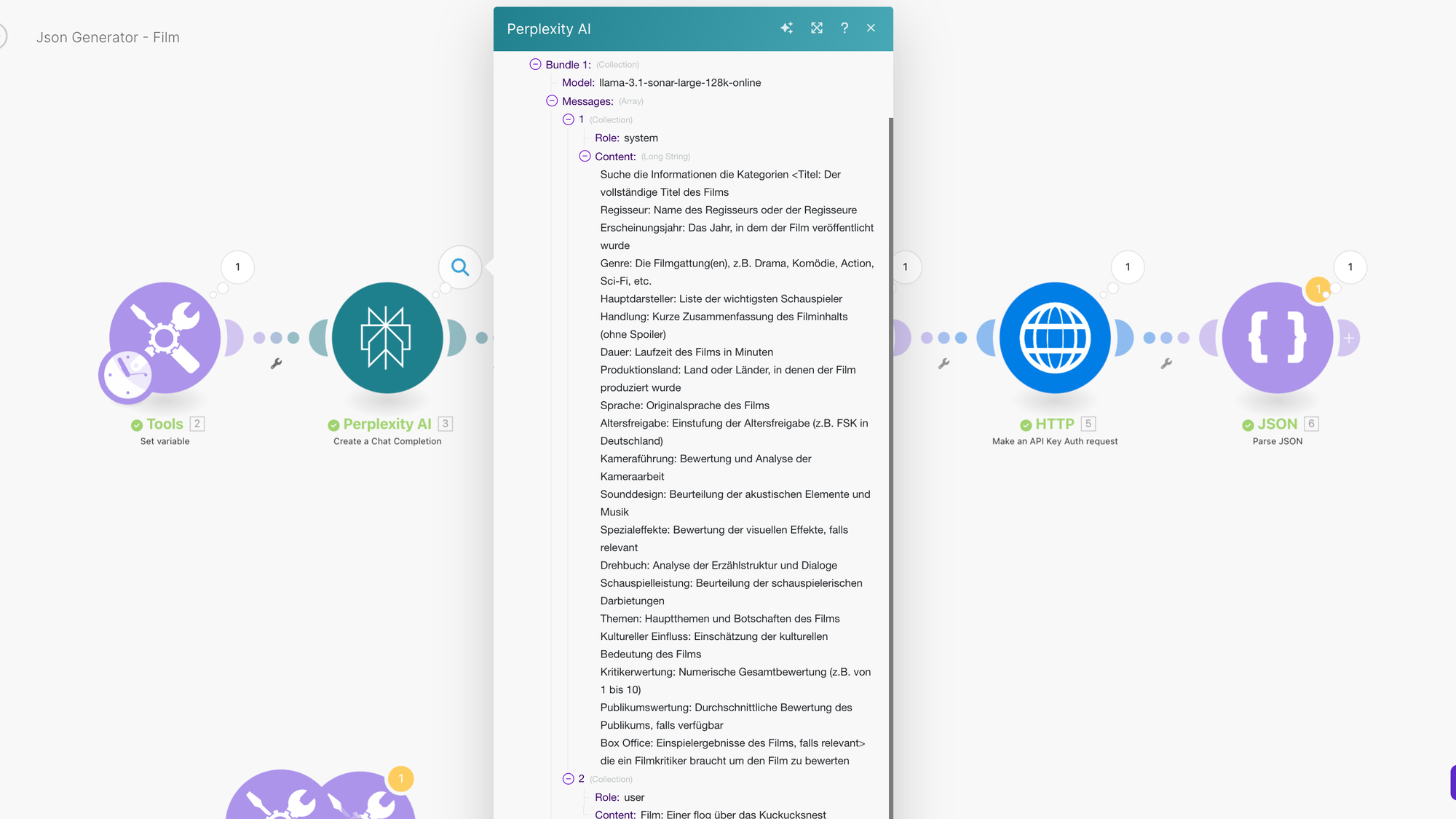
Der Prompt führt mich durch die Aufgabe und am Ende bekomme ich das Json Format das so aussieht.
{
„model“: „gpt-4o-2024-08-06“,
„messages“: [
{
„role“: „system“,
„content“: „Du bist ein professioneller Filmkritiker. Analysiere den gegebenen Film nach den vorgegebenen Kriterien und gib deine Bewertung und Erkenntnisse in der spezifizierten Struktur zurück.“
},
{
„role“: „user“,
„content“: {{4.json}}
}
],
„response_format“: {
„type“: „json_schema“,
„json_schema“: {
„name“: „filmkritik“,
„schema“: {
„type“: „object“,
„properties“: {
„titel“: { „type“: „string“ },
„regisseur“: { „type“: „string“ },
„erscheinungsjahr“: { „type“: „integer“ },
„genre“: { „type“: „array“, „items“: { „type“: „string“ } },
„hauptdarsteller“: { „type“: „array“, „items“: { „type“: „string“ } },
„handlung“: { „type“: „string“ },
„dauer“: { „type“: „integer“ },
„produktionsland“: { „type“: „array“, „items“: { „type“: „string“ } },
„sprache“: { „type“: „string“ },
„altersfreigabe“: { „type“: „string“ },
„kamerafuehrung“: { „type“: „string“ },
„sounddesign“: { „type“: „string“ },
„spezialeffekte“: { „type“: „string“ },
„drehbuch“: { „type“: „string“ },
„schauspielleistung“: { „type“: „string“ },
„themen“: { „type“: „array“, „items“: { „type“: „string“ } },
„kultureller_einfluss“: { „type“: „string“ },
„kritikerwertung“: { „type“: „number“ },
„publikumswertung“: { „type“: „number“ },
„box_office“: { „type“: „number“ }
},
„required“: [
„titel“, „regisseur“, „erscheinungsjahr“, „genre“, „hauptdarsteller“,
„handlung“, „dauer“, „produktionsland“, „sprache“, „altersfreigabe“,
„kamerafuehrung“, „sounddesign“, „spezialeffekte“, „drehbuch“,
„schauspielleistung“, „themen“, „kultureller_einfluss“, „kritikerwertung“,
„publikumswertung“, „box_office“
],
„additionalProperties“: false
},
„strict“: true
}
}
}
Alleine hätte ich das so schnell nicht hinbekommen.
Der Prompt:
Wie funktioniert der Workflow?
A. Ich gebe den Film ein, für den ich die Meta-Daten haben möchte
Hier könnte ich über die Integration von Google Sheets hunderte Filme analysieren.

B. Ich frage Perplexity nach den Daten
C. Ich wandele die Daten in ein Json Format
D. Nutze das Json Schema
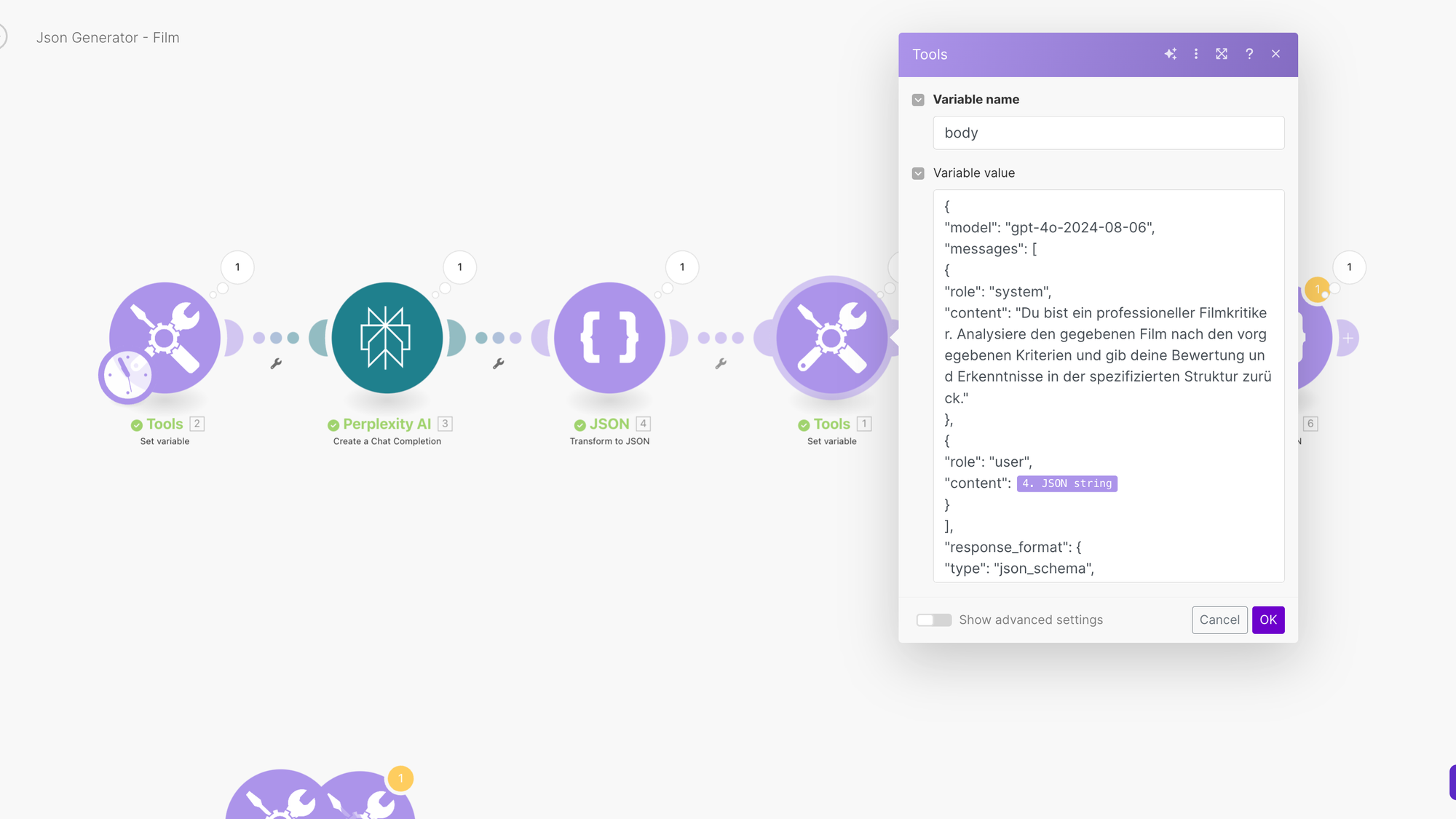
E. Sende das Schema an OpenAI
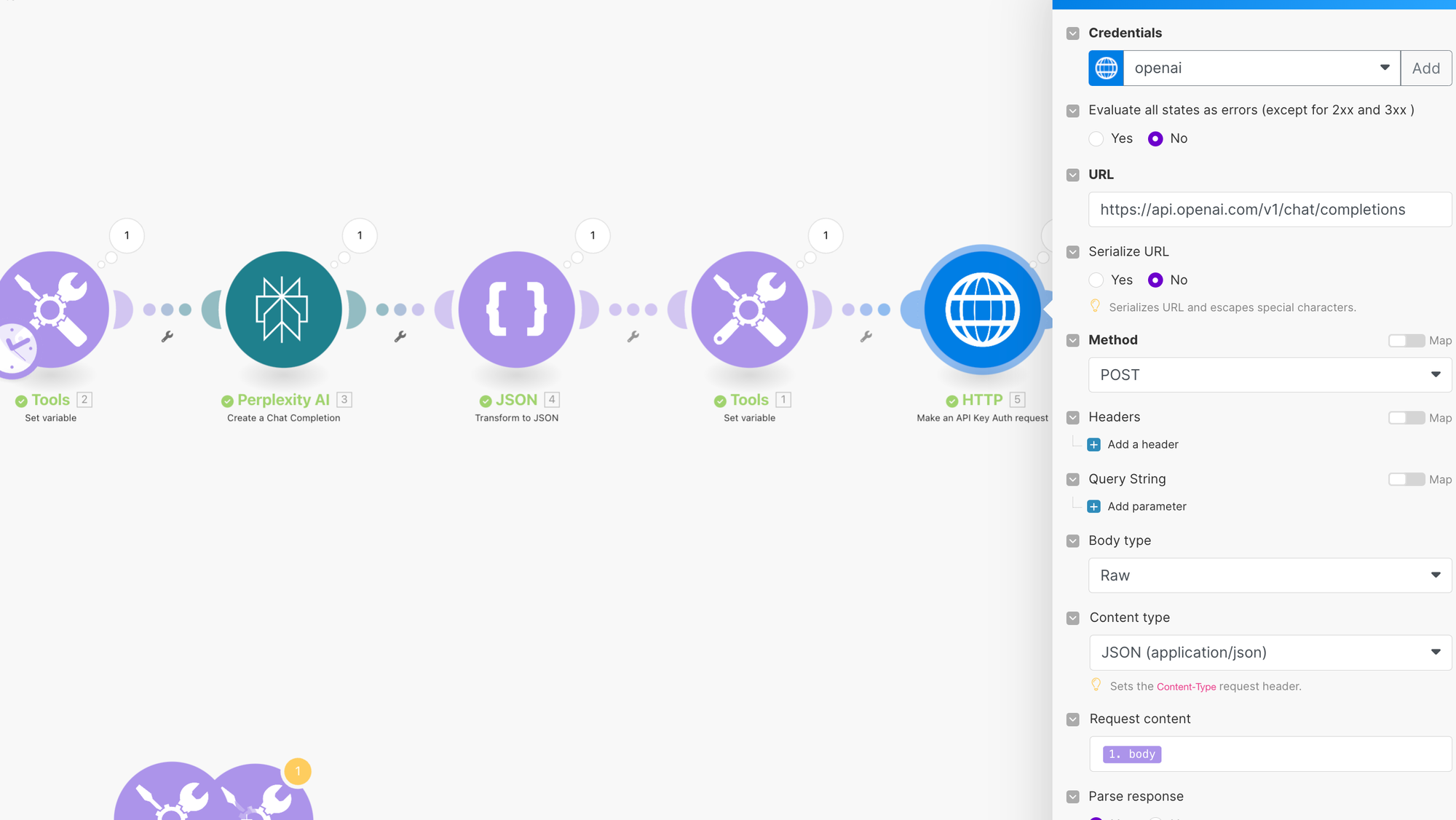
F. Bekomme eine strukturierte Ausgabe
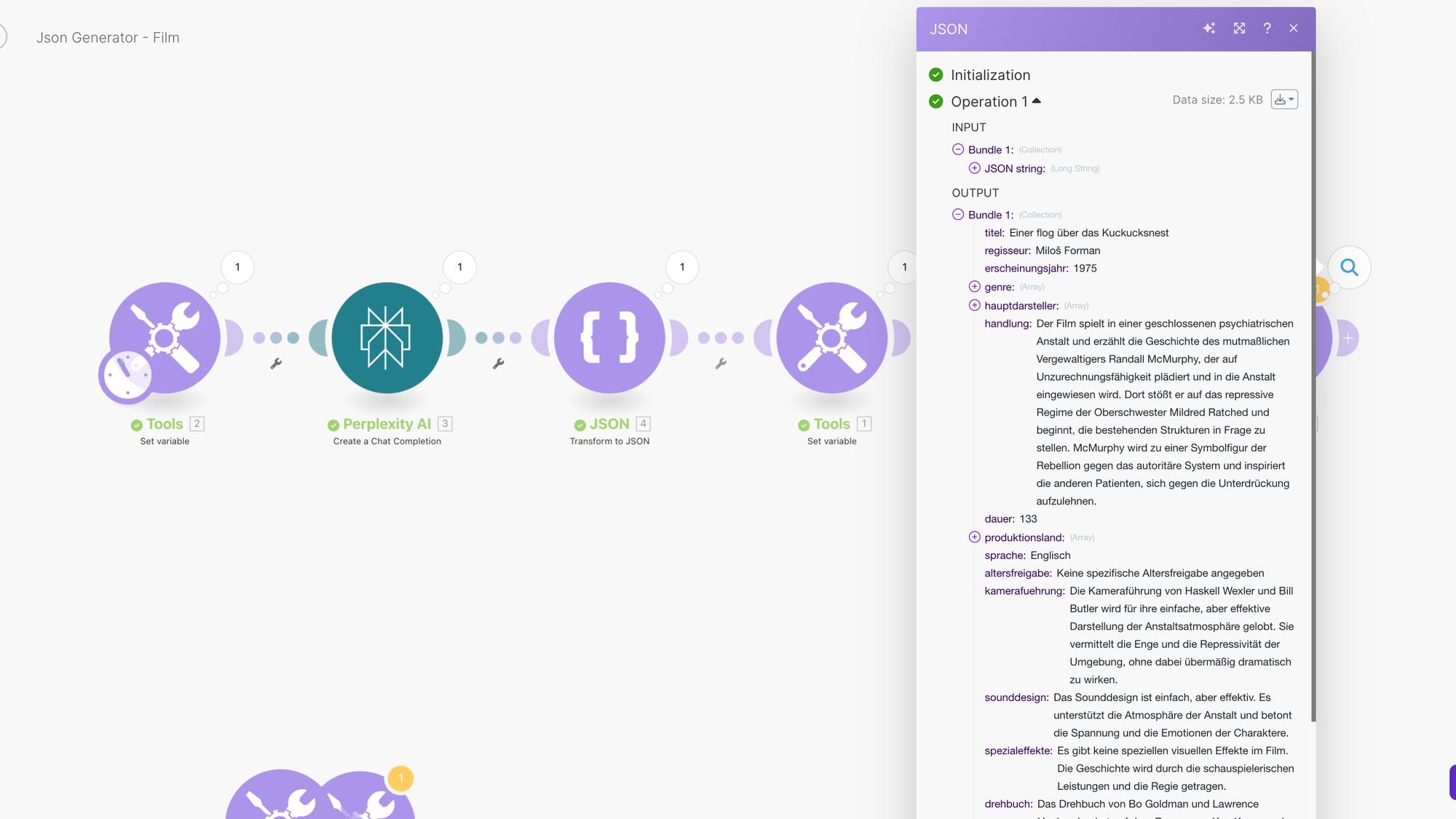
Fazit
Bisher war es für mich eine große Hürde, die Json-Struktur zu verstehen und zu erstellen, da ich darin nicht tief genug stecke.
Im Zeitalter der KI lasse ich sie das für mich erledigen. Der Prompt ist nicht perfekt; manchmal vergisst die KI etwas. Das wird sich noch ändern.
Mit dem strukturierten Output kann man nun seine Daten einfach mit Meta-Daten anreichern. Diese neue Funktionalität von OpenAI spart tausende Euro und viel Zeit beim Aufbau eigener Wissensdatenbanken.
Natürlich gibt es bestimmt schon offene Datenbanken, die diese Informationen haben, das sollte nur ein Beispiel sein, wie schnell man so ein eigenes System (mit eigenen Kategorien) aufsetzen kann. Den Workflow aufzusetzen mit dem bauen der Metaprompts hat ca. 1,5 Stunden gedauert.