#151 Baue Deine eigene KI-Wissensdatenbank: Einfache Schritt-für-Schritt-Anleitung
Worum geht es in diesem Artikel?
Ich zeige in dem Blogpost wie man mit der neuen Funktion von OpenAI zu structured Output seine eigene Wissensdatenbank aufbauen kann
Für Wissensarbeiter wird es immer wichtiger, Informationen strukturiert abzufragen. Ohne Kontrolle über die KI wissen wir oft nicht, woher die Daten stammen. Wie können wir unser Wissen mit einer KI-Datenbank besser organisieren? Der Blogpost zeigt Beispiele, wie man Daten in Vectorstores organisiert. Mit dem neuen Möglichkeiten über Structered Output von OpenAI, gibt es nun drei Möglichkeiten:
- Wir legen eine ganze PDF oder einen Artikel in einen Vectorstore. Nachteil: kaum Meta-Informationen.
- Wir wandeln PDFs und Artikel mit Tools in JSON-Formate um und speichern diese im Vectorstore. Nachteil: keine Kontrolle über die Struktur
- Wir entwickeln eine eigene Struktur, um unsere Daten zu speichern.
Gehen wir zuerst in Grundlagen um den Blog Post zu verstehen.
Wofür brauche ich Metadaten und ein Json Format?
Metadaten
Metadaten sind „Daten über Daten“. Sie beschreiben und geben Informationen über andere Daten. Stellen Sie sich ein Buch vor:
- Der Inhalt des Buches sind die eigentlichen Daten.
- Metadaten wären Informationen wie Titel, Autor, Erscheinungsjahr, Seitenanzahl.
Diese Metadaten helfen uns, das Buch zu finden und zu kategorisieren, ohne den ganzen Inhalt lesen zu müssen.
Nun zu JSON und Vector Stores:
- JSON (JavaScript Object Notation):
- Eine einfache Methode, Daten als Text zu speichern.
- Verwendet ein lesbares Format mit Schlüssel-Wert-Paaren.
- Beispiel: {„titel„: „Mein Buch„, „autor„: „Max Mustermann„}
- Vector Stores:
- Speichern Daten als numerische Vektoren (Zahlenreihen).
- Gut für die Suche nach ähnlichen Inhalten.
Warum JSON mit Vector Stores einfacher sein kann:
- Strukturierte Speicherung:
- JSON organisiert Daten übersichtlich.
- Leicht zu lesen und zu verstehen.
- Flexible Metadaten:
- Mit JSON können Sie einfach Metadaten hinzufügen.
- Beispiel: {„text“: „Inhalt“, „kategorie“: „Roman“, „datum“: „2023-08-19“}
- Einfache Integration:
- Vector Stores können JSON-Daten problemlos verarbeiten.
- Metadaten in JSON helfen bei der Organisation und Suche.
- Bessere Suchfunktionen:
- Vector Stores ermöglichen ähnlichkeitsbasierte Suche.
- JSON-Metadaten erlauben zusätzliche Filteroptionen.
Einfaches Beispiel:
{
"text": "Dies ist der Hauptinhalt des Dokuments.",
"titel": "Beispieldokument",
"autor": "Anna Schmidt",
"datum": "2023-08-19",
"kategorie": "Anleitung"
}In diesem Beispiel ist „text“ der Hauptinhalt, und die anderen Felder sind Metadaten. Vector Stores würden den „text“ in einen Vektor umwandeln, während die Metadaten für zusätzliche Suchkriterien verwendet werden können.
Diese Kombination macht es einfacher, Daten zu speichern, zu organisieren und effizient zu durchsuchen.
Suche mit Metadaten
Stellen Sie sich vor, wir haben eine Datenbank mit vielen solcher Dokumente. Hier sind einige Möglichkeiten, wie wir suchen und filtern könnten:
- Textsuche (Vector Store Funktion):
- Suche: „Wie schreibe ich eine Anleitung?“
- Ergebnis: Das System findet ähnliche Texte, einschließlich unseres Beispiels, da es eine „Anleitung“ ist.
- Filterung nach Metadaten:
- Nach Autor:
Suche: Alle Dokumente von „Anna Schmidt“ - Nach Datum:
Suche: Alle Dokumente vom „2023-08-19“ - Nach Kategorie:
Suche: Alle Dokumente in der Kategorie „Anleitung“
- Nach Autor:
- Kombinierte Suche:
- Suche: Alle Anleitungen von Anna Schmidt aus dem Jahr 2023
- Dies würde unser Beispieldokument finden.
- Teiltext-Suche im Titel:
- Suche: Alle Dokumente mit „Beispiel“ im Titel
- Datumsbereich-Filter:
- Suche: Alle Dokumente zwischen „2023-08-01“ und „2023-08-31“
- Mehrfache Kategorien:
- Suche: Alle Dokumente, die entweder „Anleitung“ oder „Tutorial“ als Kategorie haben
- Ähnlichkeitssuche mit Metadaten-Filter:
- Suche: Dokumente ähnlich zu „Wie erstelle ich ein Dokument?“, aber nur in der Kategorie „Anleitung“
Beispiel einer Pseudo-Suchfunktion:
suche_dokumente(
text_ähnlichkeit: "Wie schreibe ich eine gute Anleitung?",
autor: "Anna Schmidt",
kategorie: "Anleitung",
datum_nach: "2023-01-01"
)Diese Funktion würde:
- Ähnliche Texte zum Suchbegriff finden (Vector Store Funktion)
- Nur Dokumente von Anna Schmidt berücksichtigen
- Nur Dokumente in der Kategorie „Anleitung“ einbeziehen
- Nur Dokumente nach dem 1. Januar 2023 berücksichtigen
Unser Beispieldokument würde in diesem Fall gefunden werden, da es alle diese Kriterien erfüllt.
Diese Art von flexibler Suche und Filterung ist möglich, weil wir sowohl den Haupttext (für die Ähnlichkeitssuche im Vector Store) als auch strukturierte Metadaten (für präzise Filterung) haben.
Praxisbeispiel Chet Richards:
Angenommen, ich habe Chet Richards‘ Buch über Geschäftsstrategien im Vector Store mit Metadaten abgelegt. Nun kann ich mit einem Prompt und einem Suchfilter fragen: „Wie würde Chet Richards diese Frage beantworten? Zeige mir auch das entsprechende Kapitel.“
Youtube Videos mit Metadaten versehen
Nachdem ich ein YouTube-Video gesehen habe, möchte ich es bewerten. Dafür nutze ich folgende Kategorien:
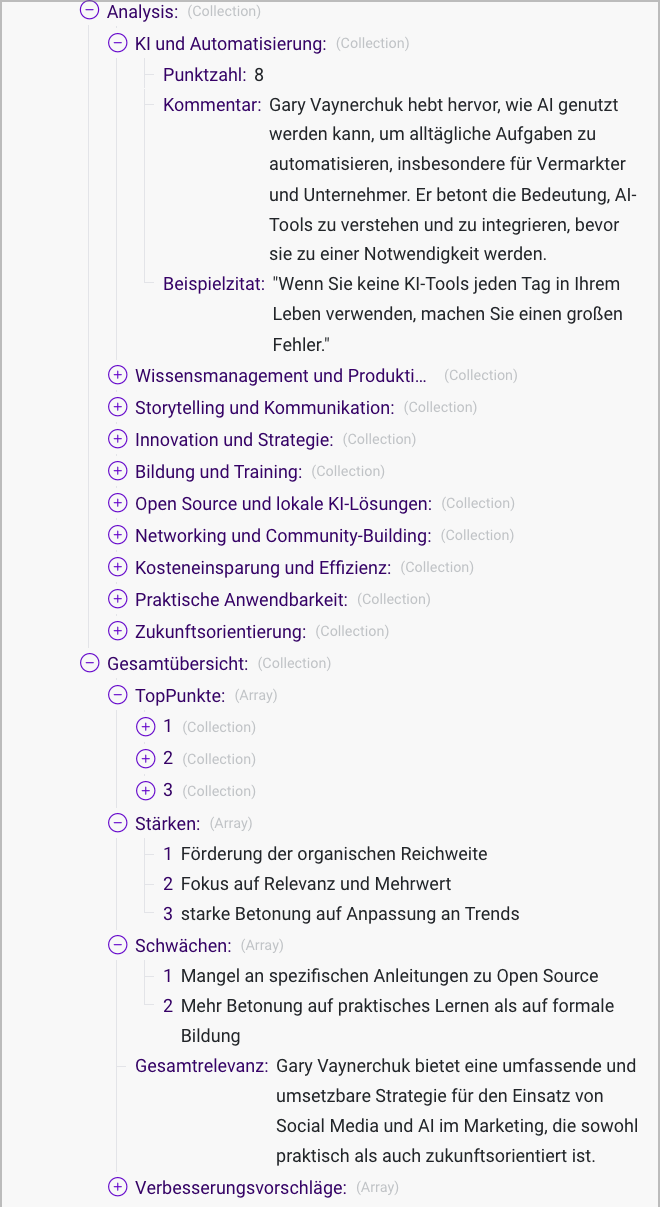
Mit diesen Metadaten kann ich dann Youtube Videos abfragen die zu einem Thema eine hohe Punktzahl haben.
Was ist SEO? Beantworte die Frage aus allen Artikel von Gary Vaynerchuk
Es gibt zwei Möglichkeiten die KI zu fragen:
A. Finde alle Artikel von Gary Vaynerchuk, die im Bereich „Automatisierung“ eine Punktzahl von mehr als 8 haben, und beantworte basierend auf diesen Artikeln die Frage: „Was ist die optimale Social-Media-Strategie für Anfänger?“.
B. Verwende die folgenden Kriterien, um Artikel zu finden:
{
„Autor“: „Gary Vaynerchuk“,
„Bereich“: „Automatisierung“,
„Punktzahl“: { „greater_than“: 8 }
}
Beantworte basierend auf diesen Artikeln die Frage: „Was ist die optimale Social-Media-Strategie für Anfänger?“.
Wie sieht ein Beispiel Workflow in Make.com aus?
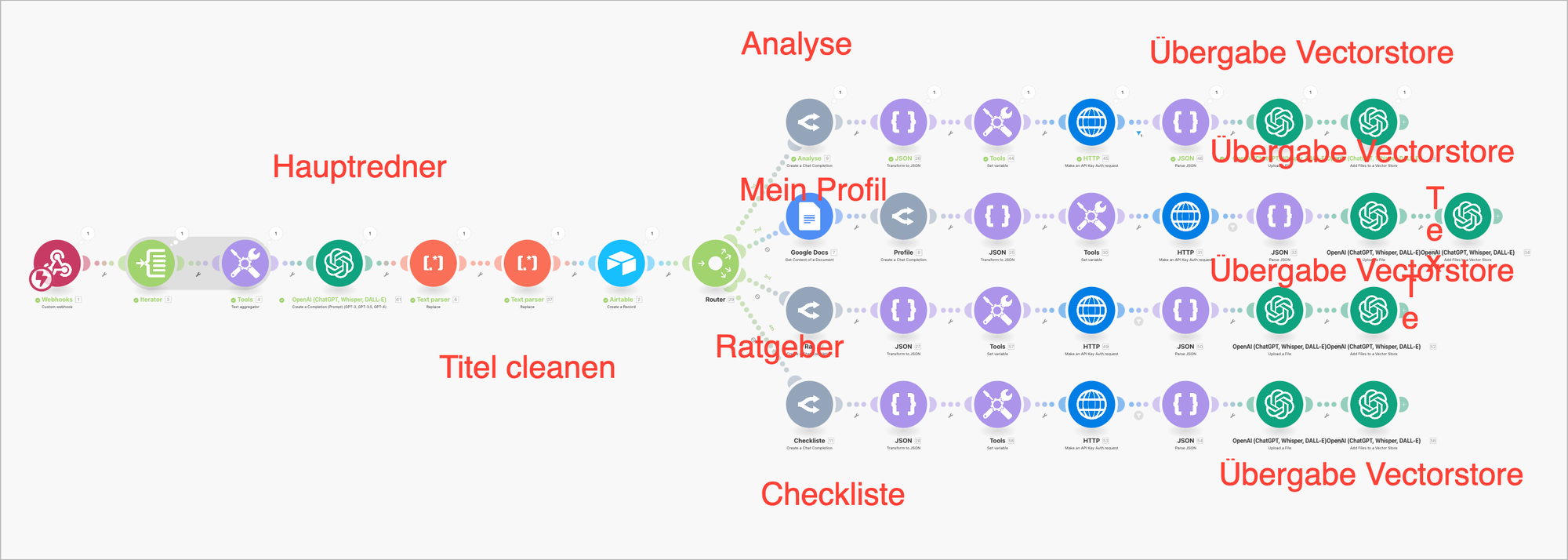
In diesem Workflow analysiere ich eine Youtube Video in vier Ebenen:
- Allgemeine Analyse
- Basierend auf meinen Präferenzen
- Einen Ratgeber
- Eine Checkliste
Die Daten werden alle in den Vector Store übergeben. Das Script hätte man auch einfacher machen können, dann ist die Fehlersuche schwieriger, so habe ich jeden Strang isoliert, das erleichtert erheblich die Fehlersuche.
Den Workflow habe ich nur so umsetzen können, weil OpenAI jetzt zu 100% Structured Output ermöglicht.
Deine Umsetzung
- Welche Daten möchtest du speichern und Abfragen?
- Baue eine Json Struktur für eine Daten
- Nutze einen KI-Workflow um diese Daten in den Vector Store zu hinterlegen
- Entwickele Workflows um mit deinem geprüften Wissen zu arbeiten
Fazit
Mit dem neuen OpenAI Update zu Structured Output ist ein neues Kapitel aufgeschlagen worden, mit KI-Systemen und Daten einfach zu arbeiten.