#150 Perfektioniere Deine Fragen an PDFs: Profi-Tipps für exakte Ergebnisse
Worum geht es in diesem Artikel?
In dem Blog Post zeige ich wie man PDFs mit Json strukturiert und diese Json Daten in den Vector Store von OpenAI bringt um bessere Ergebnisse zu erhalten
Ein Frage kam im Whatsup Chat von Karl Kratz zu dem Thema. Ich hatte schon vor Monaten mit einem kapitelweisen Ansatz gespielt die Weisheit aus einem Kapitel als Prompt zu bekommen und dann interaktiv mit einem Buch arbeiten zu können.
Dieser Ansatz ist der Ansatz für wenig priorisierte PDFs. Weil das Tool, siehe unten die Struktur vorgibt. Bei wichtigen Daten möchte ich Struktur vorgeben.
Jetzt funktioniert das.
Genaues Arbeiten
Wenn wir mit einem PDF arbeiten, streben wir exakte Ergebnisse an.
- Was enthält das Inhaltsverzeichnis?
- Was steht in Kapitel 2?
- Welche Überschriften finden wir dort?
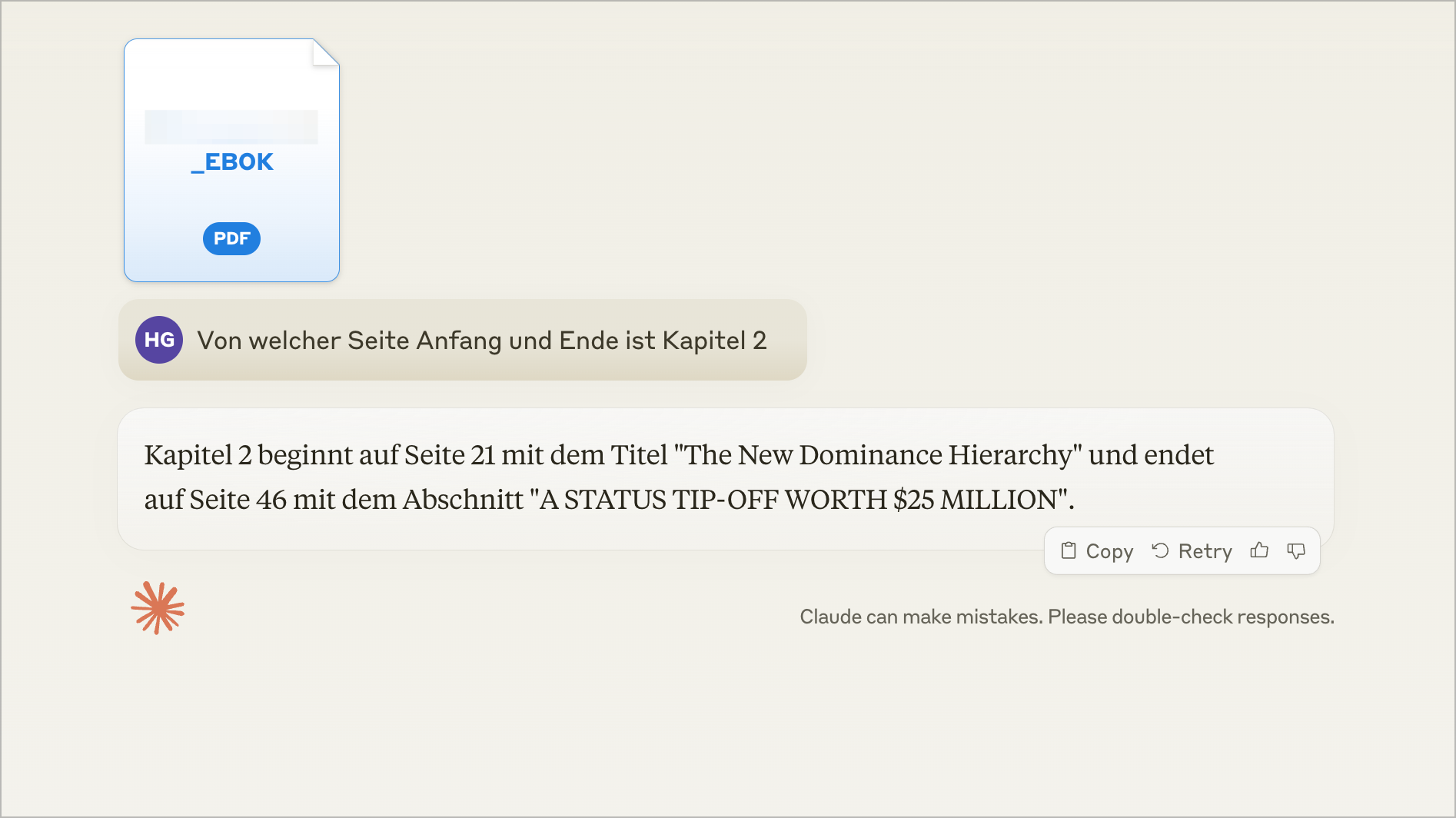
Laden wir lediglich das PDF in ChatGPT oder Claude hoch, fallen die Ergebnisse oft enttäuschend aus. Die Metadaten fehlen, und die Resultate sind häufig fehlerhaft, wie das Beispiel zeigt.
Wie gehen wir also vor?
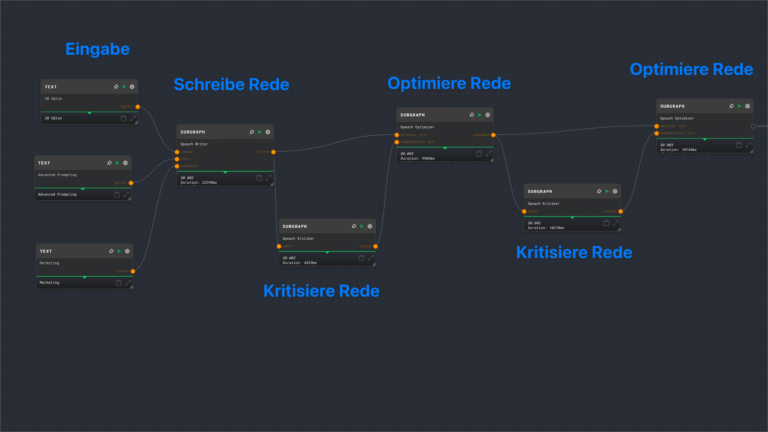
Online-Tools wandeln ein PDF in eine JSON-Datei um. Diese Datei legen wir im Vectorstore von OpenAI ab und können dann gezielt abfragen. Die Ergebnisse überzeugen.
Nanonets
Nanonets bietet einen Service, der es ermöglicht, PDFs automatisch in strukturierte JSON-Daten umzuwandeln. Der Service verwendet Künstliche Intelligenz, um relevante Informationen aus PDF-Dokumenten, wie Rechnungen, Quittungen oder Verträge, präzise zu extrahieren und sie in ein maschinenlesbares JSON-Format zu konvertieren. Dadurch können Unternehmen ihre Datenverarbeitung automatisieren und effizienter gestalten. Zudem lässt sich der Service leicht in bestehende Workflows integrieren. Wie ist das verstanden habe sind 500 Seiten frei.
Nanonets ist ein gutes Beispiel, ich schaue noch nach einem anderen Service der mir die Headlines noch besser erkennt. Dazu braucht es einen OCR Dienst.
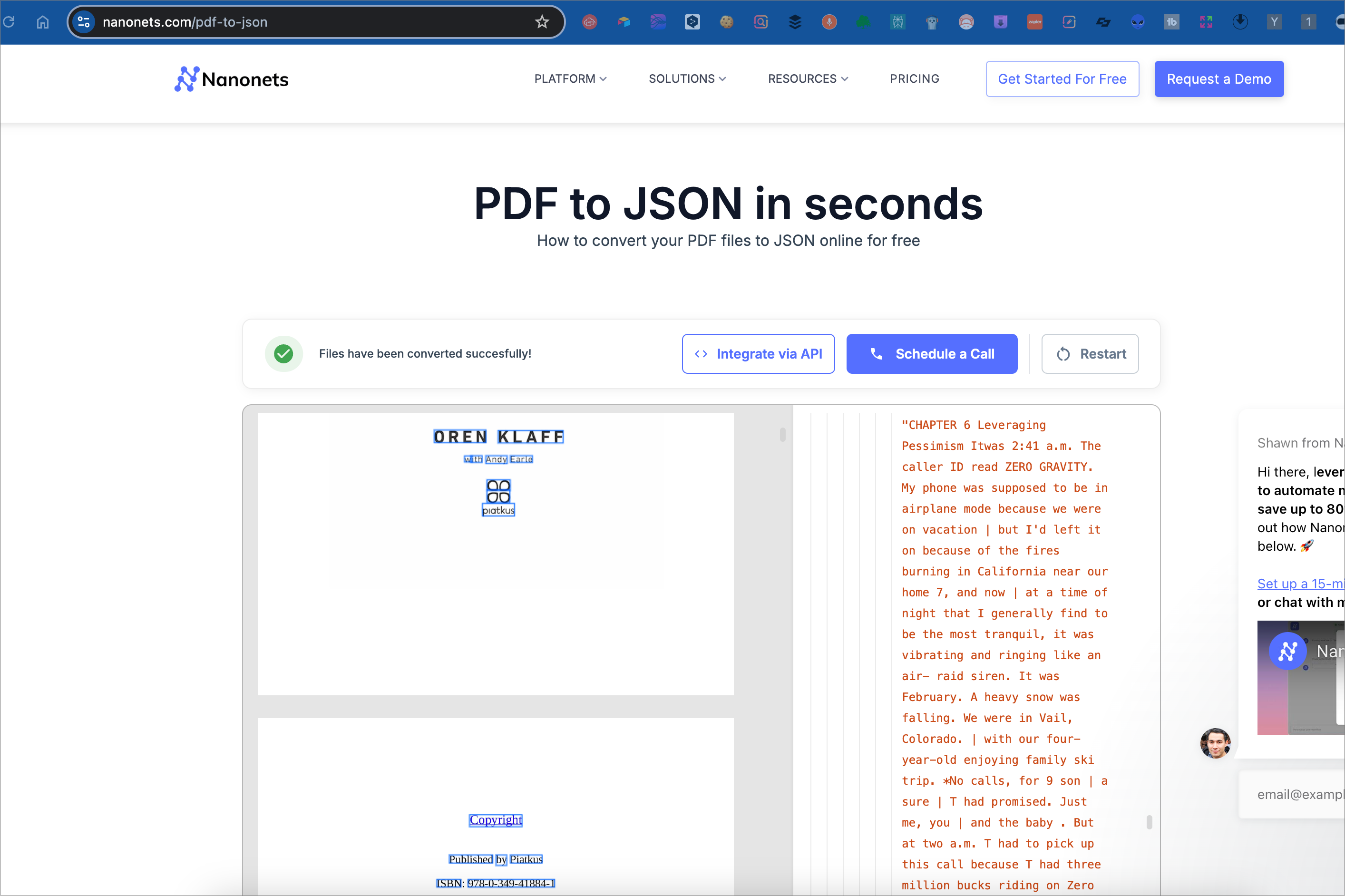
Nanonets bietet mir eine als Ergebnis eine Json Datei. Diese Json Datei lade ich in den Vectorstore von OpenAI hoch und mache ein paar Test. Ich habe ein paar Prompts getestet, ihr seht das an der Strecke in Make.
- Ab welcher Seite beginnt Chapter 2 und wann endet Chapter 2?
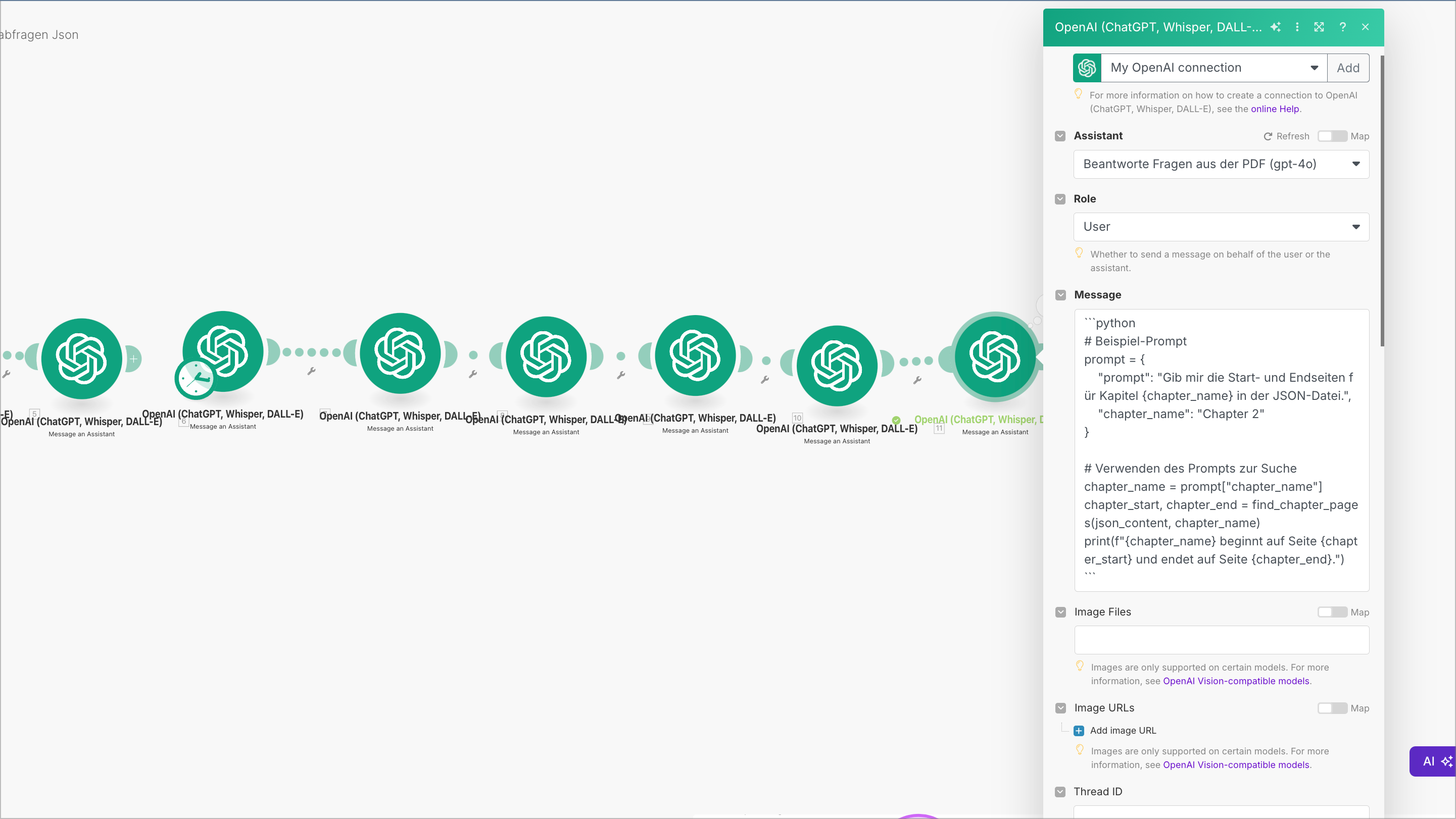
Richtiges Ergebnis:

Zu beachten ist das Nanonets auf Seite 0 anfängt zu zählen. Die Ausgabe möchte ich noch auf Json umstellen, das war der erste Test, das war schon gut.
Was ist das Inhaltsverzeichnis der PDF

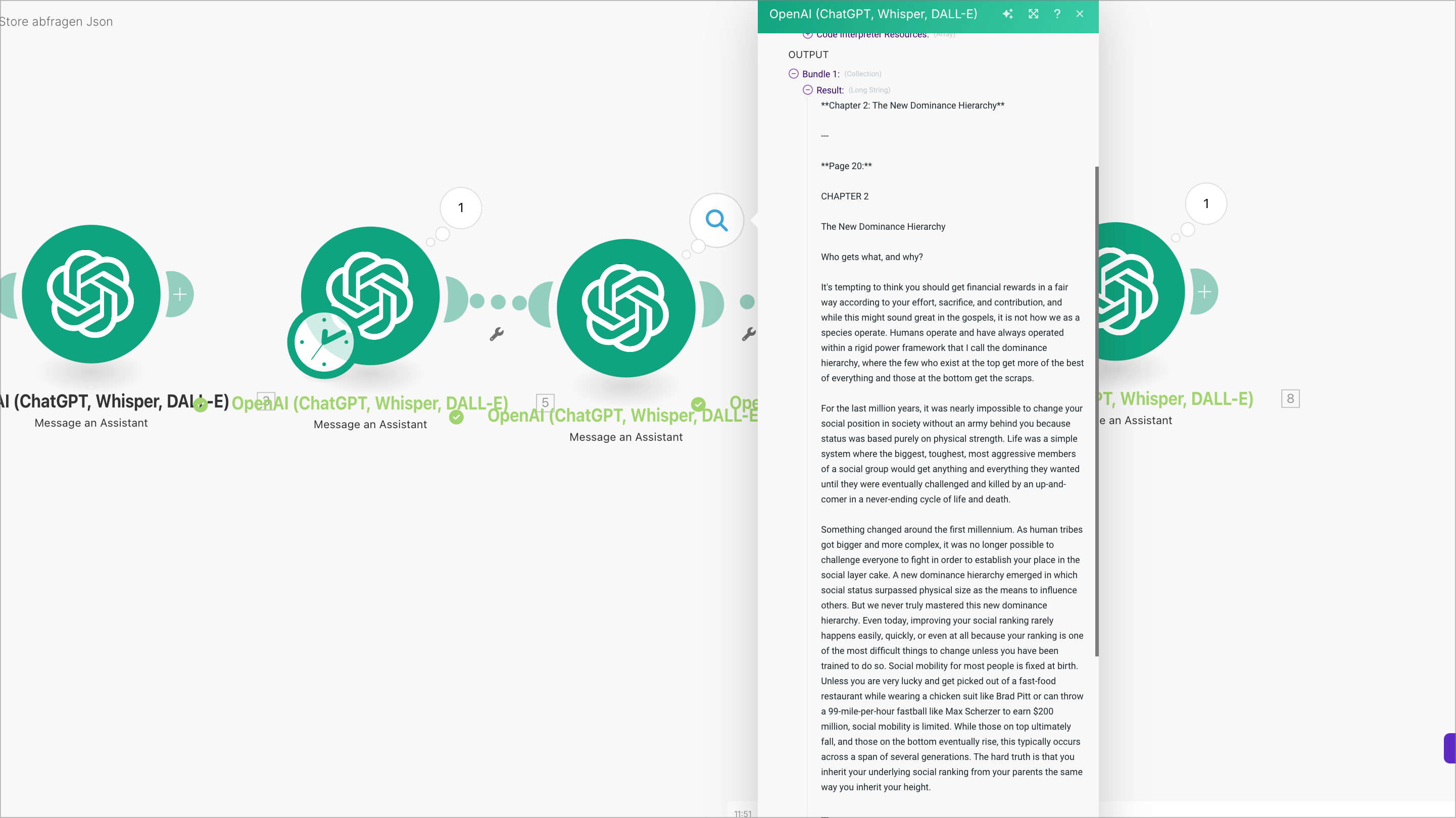
Was steht genau auf der Seite 20?
Wie kann ein Workflow aussehen um interaktiv mit einem Buch zu chatten, zu lernen?
- PDF in einen Vectorstore hochladen
- Inhaltsverzeichnis erstellen
- Die Kapitel Grenzen suchen
- Pro Kapitel eine Checkliste und interaktiven Prompt entwickeln
- Entwicklung eines Workflows um mit dem Buch/PDF zu lernen
Idealerweise in so einem Format:
Holger, ich habe deinen Kontext geprüft. Aus meinem Wissen heraus schlage ich Folgendes vor: Möchtest du, dass ich die gesamten Artefakte erstelle?
Fazit
Langfristig suche ich eine OCR-Lösung, die Headlines noch besser erkennt. Für den Anfang bin ich zufrieden.