
#109 Dreistufige Gliederungen für eine Schulungstrainings-Engine
Worum geht es in diesem Artikel?
Der Blog Post zeigt die Details einer Trainings Engine von der Planungstabelle zur Detailtabelle und wie man einen Workflow entwickelt um eine Gliederung zu erstellen.
Wie erstellt man dreistufige Gliederungen für Trainings, Konzepte, Studien usw.?
Der Blogpost zeigt den Aufbau der Schulungs-Trainings KI mit einer dreistufigen Gliederung.
In den letzten Tagen habe ich mich mit einem zentralen Element einer Schulungs-Engine beschäftigt: der Erstellung einer Planung, Schulungsdetails und Gliederungen. Es gibt zwei wichtige Tabellen: die Planungstabelle und die Detailtabelle.
Die Planungstabelle enthält verschiedene Eingabefelder wie Zielgruppe und Dauer, aber auch Felder, die von der KI berechnet werden.

Die Planung hat folgende Felder und dient zu Vorgabe der Detailplanung:
- 0.0 LLM
- 0.1 Idee Anreicherung
- 0.2 Idee Final
- 0.3 Key Points
- 0.4 Perspektiven
- 0.5 Bekannte Methoden und Lösungen
- 0.6 Auswahl von Methoden
- 0.7 Kritiker
- 0.8 Fachwissen und Rolle
- 2.0 Zielgruppe
- 2.1 Zeitdauer Kurs gesamt
- 2.1 Value Proposition
- 2.1 Kenntnisstand der Zielgruppe
- 2.2 Produkt Mission
- 2.2 Kennzahlen
- 2.2 Zeitdauer für Übungseinheit
- 2.3 Der Auftrag
- 2.3 Format
- 2.3 Probleme
- 2.4 Anzahl Module
- 2.4 Priorisierung
- 2.5 größter Engpass
- 2.5 Anzahl Inhalte pro Topic
- 2.6 Learning Characteristics
- 2.6 Anzahl Übungen
- 2.7 Workpatterns
- 2.8 Persona
- 2.9 Ziel
- 2.10 Lehrnmethode
- 4.1 Marktüberblick
- 4.2 Learning Objectives Empfehlung
- 4.3 Outline Entwurf
- 4.4 Outline Empfehlung
- 4.4.2 Outline Final do_OutlineFinal
- 4.5 Outline dreistufig do_OutlineJson
- 4.6 Finale Outline – json
- 4.7 Kontext
- 4.7 erweiterter Kontext
- 6.1 Video Art
- 6.2 Video Länge
- 6.3 Ton
- 6.4 Szenen und Output
- 6.5 Charakters
- 6.6 Sprachstil
- 6.7 Ausgabe Formate
- 6.6 A1_LernerKontext_Engpass
Sobald die Planung steht, kann ich auf einen Knopf drücken und die Detailplanung für jeden Kapitelpunkt wird automatisch erstellt.

Eine grobe Übersicht über den Workflow findet sich hier:
Die Detailtabelle hat diese Felder:
0.1 Ebene 1 Ueberblick
0.2 Ebene 2 Ueberblick
0.3 Ebene 3 Ueberblick
- Ebene1
- Ebene2
- Ebene3
- 2.1 Vorschlag Videoformat
- 2.2 Video Länge
- 2.3 Tone des Videos
- 2.4 Vorschlag Structure
- 2.5 Scenes
- 2.6 Visuals
- 2.6 Visuals
- 3.1 Warum das Kapitel
- 3.2 Lernziele
- 3.3 Zitate
- 3.4 Zusammenfassung
- 3.5 Literaturhinweise
- 3.6 Videos
- 3.7 Merkbare Geschichte
- 3.8 Dafür und Dagegen
- 3.9 Was weiß ich schon
- 3.10 Wie hängt das Kapitel mit anderen zusammen
- 4.1 Lerntext
- 4.2 Übungen
- 4.3 Teacher Wissen
- 4.4 Sokratischer Dialog
- 4.5 Kritisches Denken
- 4.6 Charakter für Inhalt
- 4.7 Laterales Denken
- 4.8 Concept Map
- 4.9 Role play
- 4.10 Bilder
- 5.1 FAQ
- 5.2 HowTos
- 5.3 Poster
- 5.4 Anki-Cards
- 5.5 Lückentexte
- 5.6 Puzzle
- 5.7 Reflection und Journale
- 5.8 Glossar
- 5.9 Storyboard
- 5.10 Scenarios
- 5.11 Multiple Choices
- 5.12 Lückentexte + Story
- 5.13 Self Assessment Checkliste
- 5.14 Verschiedene Startpunkte
- 6.1 Markdown
- 6.2 Text
- 6.3 Slides
- 6.4 PDF
- 6.5 Audio
- 6.6 Google Doc
- 6.7 Markdown für Gamma
- 6.8 eBook
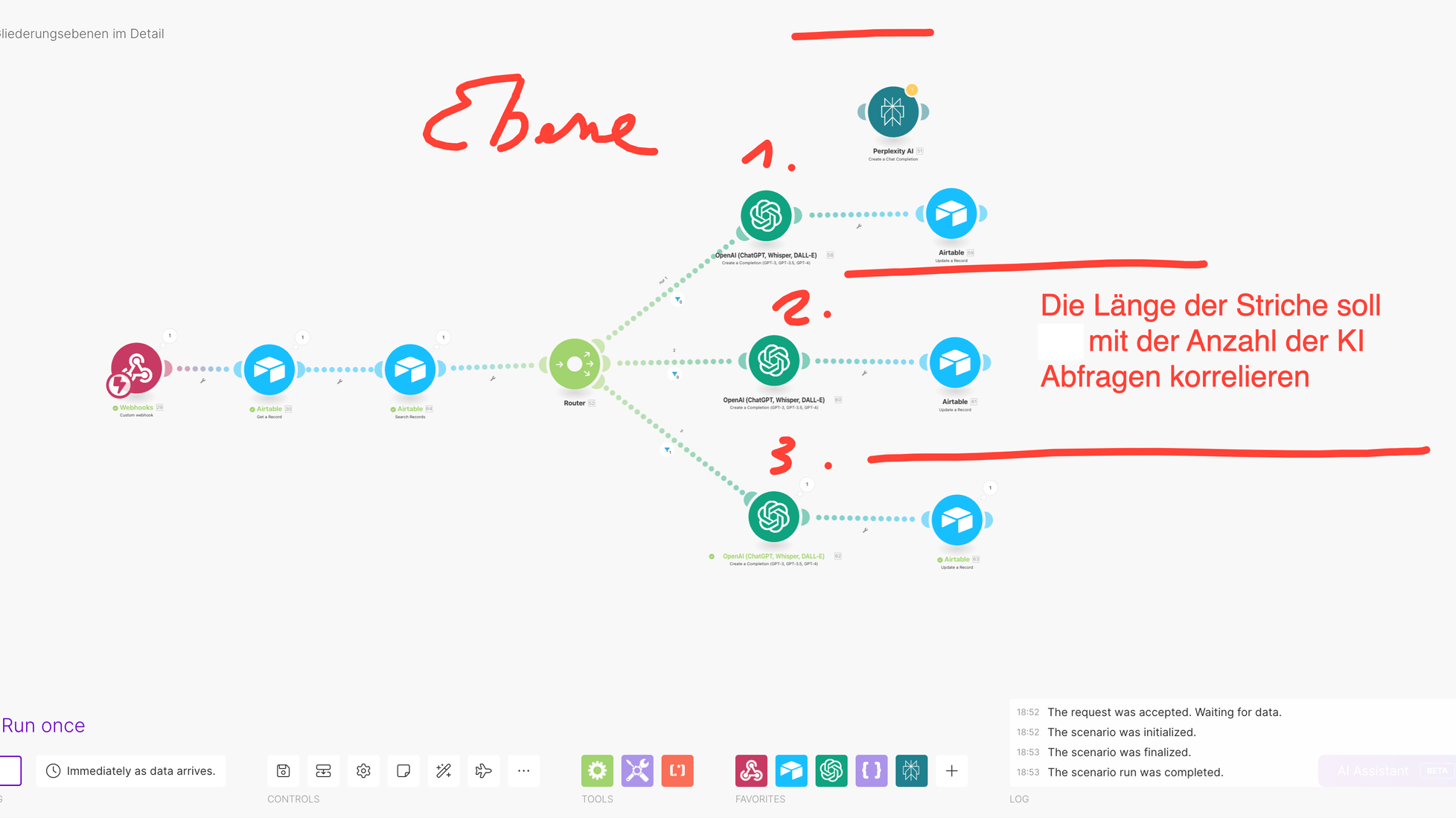
Dabei fließen viele Daten zusammen, aber das Herzstück ist die Erstellung der Gliederung. Die oben genannten Felder werden für Ebene 3 ausgefüllt, während für die Ebenen 1 bis 2 reduzierte Antworten verwendet werden.
Jetzt arbeite ich noch an der Implementierung des KI-Workflows für die einzelnen Fragen. Das erfordert viel Fleißarbeit. Im Workflow werden Abfragen zur Perplexity, zu realen Daten und zu einem Prüfmechanismus eingebaut, mit dem ich Inhalte aus PDF-Dokumenten extrahieren kann.
Wie sehen die Workflows aus?
Ich erstelle aus jeglicher dreistufigen Gliederung:
- Eine nummerierte Gliederung im x., x.x, x.x.x. Format
- Aus diesem Format wird mitActive Pieces ein Json Format erzeugt

Das JSON Format

Aus diesem Json Format erstellt der folgende Make Workflow diese dreistufige Gliederung in der Tabelle Schulungsdetails.
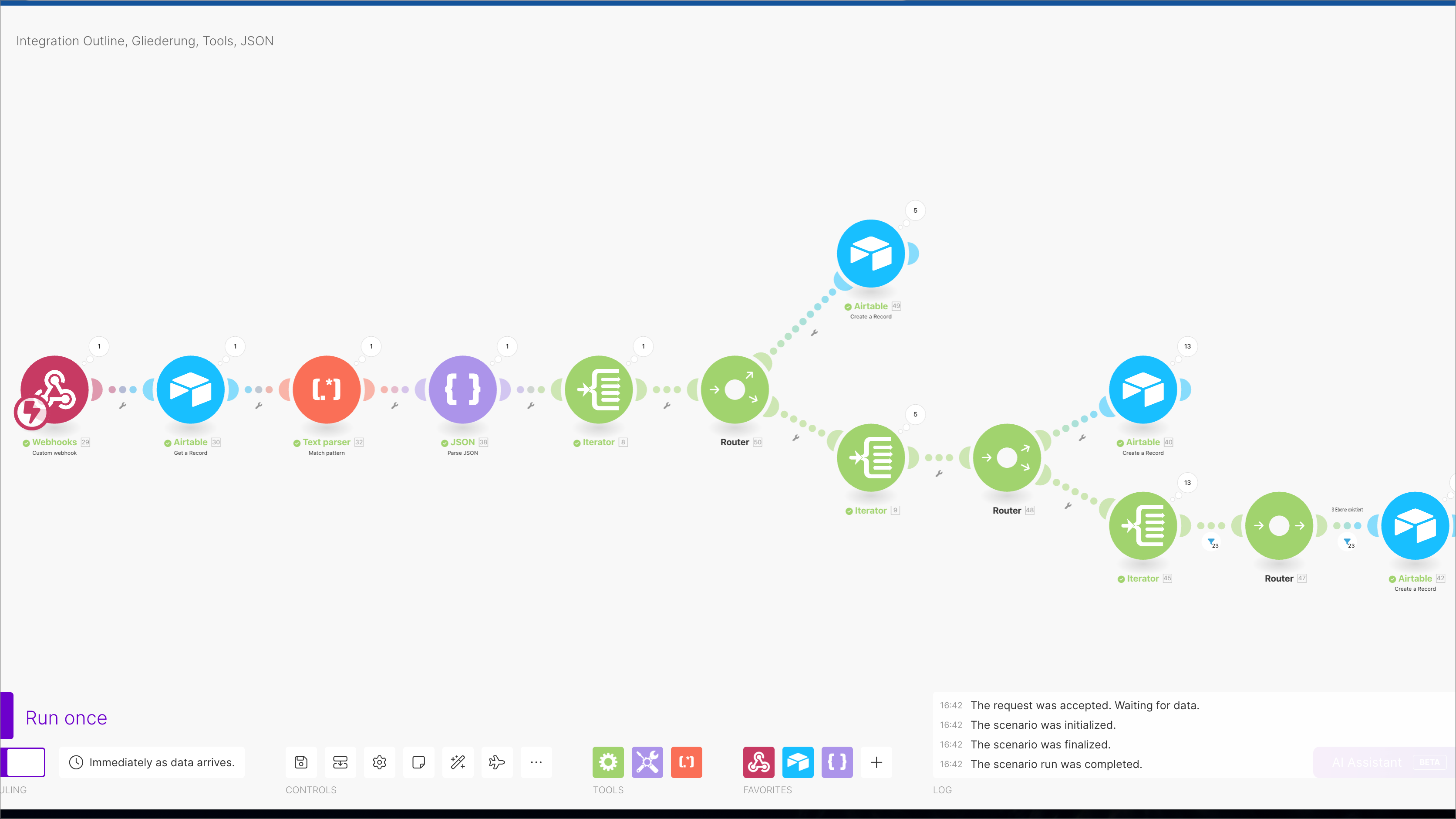
Wenn die Gliederung erstellt ist, kann jede Zeile mit den Inhalten bearbeitet werden. Der Rumpf des Skriptes sieht folgendermaßen aus:
Fazit
Nachdem ich den Workflow erfolgreich abgeschlossen habe, steht nun die Implementierung der Abfragen an. Das Erstellen des Markdown-Outputs für LiaScript erfordert zwar etwas mehr Aufwand, aber das sollte kein Problem sein. Herausfordernd wird noch eigene PDFs als Grundlage für einen Kritiker und Optimierer einzubringen. Ich bin bereit, meinen ersten Online-Kurs zu entwickeln.
Anhang:
Der bisherige Weg war geprägt von einem Prozess des Ausprobierens, der viele Stunden in Anspruch genommen hat. Im Folgenden werden einige Zwischenschritte aufgezeigt.





